概述
Xillybus最常见的使用场景是数据采集。此页面显示如何开始将数据(data)从 FPGA 传输到主机(host)。
有关 FPGA内部与 Xillybus 交互的更详细视图,请参阅Xillybus FPGA designer's guide 。
如果应用程序具有较高的传输速率(data rate),还建议阅读 Getting Started guide for Linux 第 5 章或微软 Windows(Microsoft Windows)中有关此内容的指南。
主机的侧面
为了理解 Xillybus 是如何工作的,最简单的方法是从电脑端入手: 这个命令可以用来对磁盘上的文件执行数据采集:
$ cat /dev/xillybus_read_32 > capture-file.dat
“cat” 是一个标准的 Linux 命令,它从文件读取所有数据,并将此数据写入标准输出(standard output)。在此示例中,输入不是常规文件,而是设备文件(device file)。此输入由来自 FPGA的数据数据流(data stream)组成。标准输出有一 redirection ,因此此数据被写入磁盘上的文件。
这不是一个人为的例子: 在一些使用场景下,这才是实际使用 Xillybus 换数据采集的正确方式。最好使用“dd”以获得特定数量的数据。更常见的是,使用专用计算机程序从设备文件读取数据。每个应用程序都有自己的首选方式来使用数据。
因此,无论您喜欢哪种编程语言,或者您使用 Linux 还是 Windows,都没有关系。从 FPGA 接收数据的电脑软件只需要和“cat”一样: 打开一个文件,并从中读取。有一个单独的页面介绍了 file I/O的标准编程技术。有关 Xillybus 编程技术的更多详细信息,请参阅 Linux 和 Windows的编程指南。
适用于数据采集的逻辑
现在让我们看看 FPGA中发生了什么。 Xillybus IP core 和应用逻辑通过 FIFO交互: 应用逻辑将数据写入 FIFO, Xillybus 确保这些数据(data)到达主机。如果您不熟悉此概念,则有一个单独的页面解释 FIFOs 的工作原理。
Xillybus的演示包的(demo bundle)包含一个名为 xillydemo.v的文件。这是与 IP core交互的 Verilog 代码。演示包的中还有一 VHDL 文件: xillydemo.vhd。但是,下面的示例是在 Verilog中。
Xillybus IP core的例化(instantiation)发生在 xillydemo.v中。(或 xillydemo.vhd)。这些部分与上面的数据采集示例和 "cat" 命令相关(其他部分跳过)。
// Wires related to /dev/xillybus_read_32
wire user_r_read_32_rden;
wire user_r_read_32_empty;
wire [31:0] user_r_read_32_data;
wire user_r_read_32_eof;
wire user_r_read_32_open;
[ ... ]
xillybus xillybus_ins (
[ ... ]
// Ports related to /dev/xillybus_read_32
// FPGA to CPU signals:
.user_r_read_32_rden(user_r_read_32_rden),
.user_r_read_32_empty(user_r_read_32_empty),
.user_r_read_32_data(user_r_read_32_data),
.user_r_read_32_eof(user_r_read_32_eof),
.user_r_read_32_open(user_r_read_32_open),
[ ... ]
.bus_clk(bus_clk),
[ ... ]
);
IP core的端口的含义在Xillybus的逻辑应用程序接口(logic API)的指南中有详细说明。
xillydemo.v中有一 FIFO 的例化。这 FIFO 是一 single-clock FIFO,它适合原始 Verilog 代码中演示的回环(loopback)。对于数据采集应用程序, dual-clock FIFO 更合适,因为数据采集逻辑(data acquisition logic)通常依赖于其自己的时钟。
因此,您可以将 xillydemo.v 更改为执行数据采集的模块,如下所示: 删除 single-clock FIFO 的例化(称为 fifo_32x512)。改为插入:
assign user_r_read_32_eof = 0;
dualclock_fifo_32 fifo_32
(
.rd_clk(bus_clk),
.rst(!user_r_read_32_open),
.rd_en(user_r_read_32_rden),
.dout(user_r_read_32_data),
.empty(user_r_read_32_empty)
.wr_clk(capture_clk),
.wr_en(capture_en),
.din(capture_data),
.full(capture_full)
);
dual-clock FIFO
dualclock_fifo_32 是标准 dual-clock FIFO(standard dual-clock FIFO)。需要使用 FPGA的开发软件将其创建为 IP 。此 FIFO 的深度应为 512 elements 或更高。由于 FPGA 软件之间的差异,端口的名称可能与上面显示的不同。不过,应该很容易推断出如何连接 FIFO的端口。
再一次,有一个介绍 FIFOs的页面,如果您还不熟悉的话。
FIFO的端口中有几个直接连接到 Xillybus的 IP core: @rd_clk、 @rd_en、 @dout 和 @empty。请注意,这些连接与演示包的中的完全相同。 IP core 使用这四个信号从 FIFO拉出数据。这始终是将这些端口与 IP core连接的正确方法。
请注意, @rd_clk 连接到 @bus_clk。这个信号来自 Xillybus的 IP core。换句话说, IP core 决定了 FIFO的一侧使用的时钟。
至于 @rst,注意是接 !user_r_read_32_open的。只有在主机上打开相关的设备文件时, @user_r_read_32_open 才为高电平。因此,当文件未打开时, FIFO 将被重置。因此,当主机打开设备文件时, FIFO 为空: 如果 FIFO的存储空间中存在上一个会话的剩余物,则在关闭设备文件时将其删除。
这种行为是我们通常对数据源代码的期望。但是,如果您希望 FIFO 在设备文件关闭时保留其数据,请将其他东西连接到 @rst。或者可能将 @rst 保持在低位。
请注意, @user_r_read_32_eof 在此示例中为零,在演示包的中也是如此。此信号可用于将 end-of-file 发送到主机。 应用程序接口(API)指南中有更多相关信息。
与应用逻辑的接口
在数据采集应用程序中,总会有某种应用逻辑生成数据以传输到主机。这部分不同于一个应用程序到另一个应用程序,因此与本讨论无关。我们将专注于将此数据发送到主机。
这部分非常简单: 应用逻辑将这些数据写入 FIFO。写入 FIFO 的数据作为连续的数据数据流到达主机上的计算机程序。
因此,应用逻辑使用标准约定写入 FIFO。在上面的示例中,这显示为 @capture_clk、 @capture_en、 @capture_data 和 @capture_full。这个逻辑只需要将数据放在 @capture_data 中,控制 @capture_en 就可以正确写入 FIFO了。请注意,应用逻辑使用其自己的时钟写入 FIFO。
数据 flow(data flow)
这是一个简化的框图,说明了数据 flow 从应用逻辑到主机上的应用程序(user application program)。
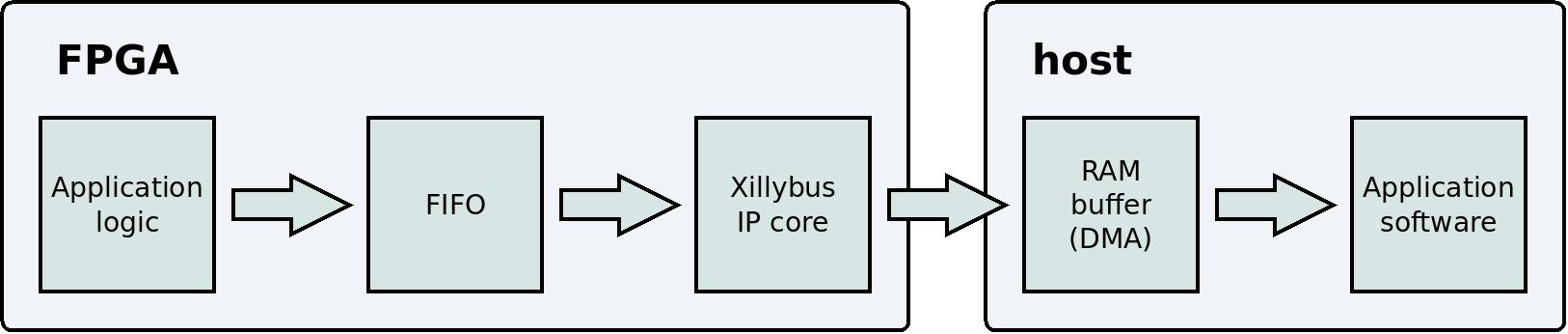
请注意,此框图中省略了两个技术细节: PCIe block 和 kernel 驱动程序没有展示,因为它们与用户对数据 flow的感知无关。 Xillybus 的正确使用方法是忘记这些细节,专注于应用逻辑和应用软件(application software)。
不需要把数据整理成 packets: 应用逻辑和计算机之间的通信通道是连续的数据流(stream)。 IP core 和驱动程序确保数据 flow 的行为与其他数据流协议(stream protocols)相同,例如 pipes 位于程序(programs)和 Linux之间。具有类似行为的另一个协议(protocol)是 TCP/IP。换句话说,无论向 FIFO写入多少数据都无关紧要。这些数据很快就会到达主机上的应用程序。
将数据组织成 packets 并将 IP core的 DMA 缓冲区调整为这些 packets的尺寸是一个常见的错误。这样做没有任何好处。即使数据在具有恒定尺寸的 packets 中发送,也无需将 IP core 调整为该尺寸。
但是,如果 FIFO 变满了怎么办?
关于 FIFO 的基本规则之一是: 如果 @full 端口为高电平,则 @wr_en 必须为低电平。简单来说: 不要写入完整的 FIFO。那么如果发生这种情况怎么办?处理这种情况会使应用逻辑变得相当复杂。
简短的回答是 FIFO 永远不应该变满: 在正常操作条件下,会主动防止这种情况发生: IP core 从 FIFO 读取数据,并将这些数据复制到主机的 RAM中。这种情况发生得足够快,足以防止 FIFO 充满。通常, FIFO 不需要比 512数据 elements(data elements)更深。
但是,如果应用逻辑写入 FIFO 的速度过快, FIFO 可能会变满。换句话说,如果应用逻辑的平均传输速率超过 IP core的限制(如针对每种类型的 IP core所宣传的那样),则 IP core 将无法足够快地从 FIFO读取数据。
另一种可能性是应用软件(例如上例中的“cat”)无法足够快地从设备文件读取数据。因此,主机处的 RAM 缓冲区将变满,这也会阻止 IP core 从 FIFO 读取(因为 IP core 没有地方写入数据)。结果,发生了溢出(overflow)。这可能是因为应用软件写入不正确。另一个可能的原因与操作系统有关,下面将进一步讨论。
主机上 RAM 缓冲区的大小取决于 Xillybus IP Core。例如,对于 xillybus_read_32 和 xillybus_write_32 (在 IP core 中是演示包的的一部分),此尺寸为 4 MBytes 。 IP Core Factory 允许创建需要更大缓冲区的自定义 IP cores 。
综上所述: 防止溢出是为 IP core选择正确参数的问题: 首先,这 IP core 应该能够处理传输速率。此外,主机的 RAM 缓冲区应该足够大。这确保即使应用程序不从设备文件读取数据,数据流仍可继续。
尽管如此,如果 FIFO 变满,则常见原因是系统设计出现错误。选择溢出的一个常见原因是高估了计算机处理传输速率的能力。
尤其是,如果将数据写入磁盘上的文件(如上面的 "cat" 命令),则最大传输速率可能比人们想象的要慢。原因是操作系统通常具有较大的 disk cache (可能有许多 Gigabytes)。如果用比 disk cache更小的数据来测量磁盘的传输速率,结果将过于乐观: 在实际发生之前,操作系统会假装已经完成将数据写入磁盘。实际上,数据只到 cache,实际写入磁盘发生在后面。只有在处理大量数据时才会显示此错误。
CPU的剥夺
不幸的是,溢出有一个不可避免的可能性: 允许操作系统(Linux 或 Windows)无限期剥夺 CPU 的任何 user-space process 。也就是说,读取数据的计算机程序可以突然停止工作一段时间,然后再恢复正常运行。这个时间段没有限制。允许任何 non-real-time operating 系统像这样随机暂停 processes 。
然而,这些操作系统仍然可以使用数据采集。这主要是因为长期剥夺 CPU 通常被认为是一种不良特征。所以这些停顿通常很短。
在这些暂停期间, IP core 继续填充主机上的 RAM 缓冲区(凭借 DMA,因此不需要处理器的干预)。当计算机程序取回 CPU 时,它可以快速消耗所有已经积累的数据。补偿 10 ms 暂停的 RAM 缓冲区通常就足够了。但是,在IP Core Factory上创建自定义 IP core 时,可以请求更大的缓冲区。
尽管如此,仍有可能暂停时间过长。结果, RAM 缓冲区将变满,因此 FPGA 上的 FIFO 将变满。这个溢出(overflow)的结果就是数据会丢失。这永远不应该发生,也可能永远不会发生。但如果是这样呢?
检测溢出
建议的解决方案是在 FIFO 变满时终止数据数据流: 逻辑在连续的数据的最后一个元素之后立即将 EOF (end-of-file) 发送到主机。那么让我们考虑一下如果主机使用 "cat" 命令消耗数据会发生什么情况,如上所述:
$ cat /dev/xillybus_read_32 > capture-file.dat
通常情况下,这个命令会继续运行,直到 CTRL-C停止运行。但是,如果 FIFO 在 FPGA中已满,这个命令将正常终止,就像它在完成复制常规文件后所做的那样。输出文件将包含在 FIFO 已满之前收集的所有数据。
总结一下这个方法: 所有写入 capture-file.dat 的数据都保证无错误且连续。如果数据采集系统由于 CPU 剥夺而无法保持连续性,则结果是较短的输出文件。但是文件的内容是可以依赖的。
为了实现此解决方案,请将 dualclock_fifo_32的例化替换为:
eof_fifo fifo_32
(
.rd_clk(bus_clk),
.rst(!user_r_read_32_open),
.rd_en(user_r_read_32_rden),
.dout(user_r_read_32_data),
.empty(user_r_read_32_empty)
.wr_clk(capture_clk),
.wr_en(capture_en),
.din(capture_data),
.full(),
.eof(user_r_read_32_eof)
);
eof_fifo 的定义在单独的页面上给出。
请注意, @user_r_read_32_eof 连接到此 FIFO的 @eof 端口。这就是逻辑在必要时将 EOF 发送到主机的方式。另请注意,没有任何东西连接到此 FIFO的 @full 端口: 不再需要监控这个信号。如果 FIFO 满了,就没什么可做的了。 EOF 机制确保主机在所有有效数据用完后重新启动数据流。
数据 playback(Data playback)
反方向呢?像这样的事情怎么样?
$ cat playback-data.dat > /dev/xillybus_write_32
这工作原理相同: "cat" 命令从磁盘上的文件读取数据,并将数据写入设备文件。在 FPGA上, IP core 将此数据写入 FIFO。应用逻辑从 FIFO读取数据。思路相同,只是方向相反。
这是一个简化的框图,说明了从数据 flow 、主机上的应用程序到应用逻辑。
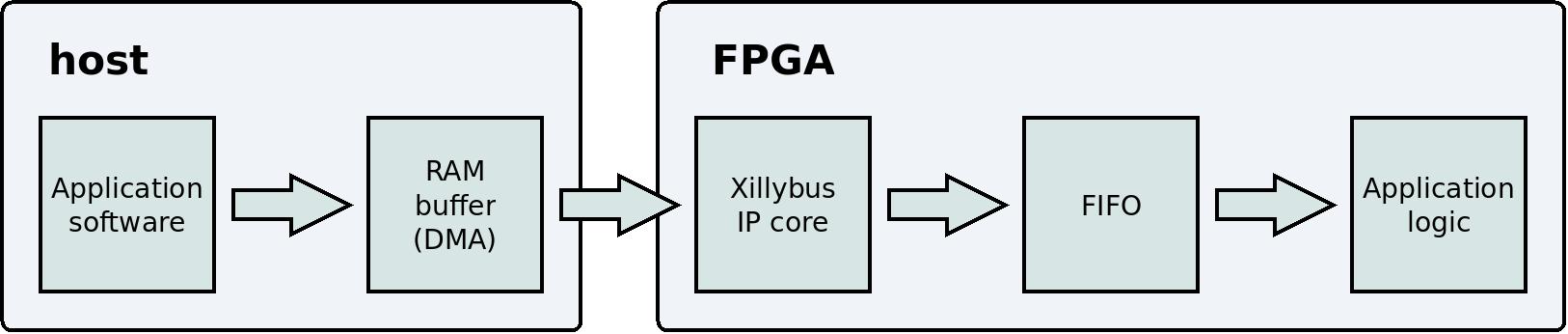
与数据采集类似,没有丢失数据的风险: IP core 已满时不会写入 FIFO 。结果,主机的 RAM 中的缓冲区也可能变满。发生这种情况时,主机上的应用程序会等待(通过休眠),直到应用逻辑从 FIFO读取足够的数据。
与数据采集的另一个相似之处是,只要应用程序继续足够快地写入数据, FIFO 就永远不会变空。为了保证这一点,同样的考虑是相关的: IP core的规格以及应用程序必须支持所需的传输速率。
当满足这些条件时,应用逻辑可以在需要数据时从 FIFO 消耗数据。 underflow 永远不应该发生。
异步数据流(Asynchronous streams)与同步数据流(Synchronous streams)
这个主题没有直接关系,但仍然值得简要讨论一下。
在数据采集应用程序中,主要目标是保持连续的数据流。因此, IP core 会尽快将数据从 FIFO 移动到主机的 RAM 缓冲区。主机上的应用程序是否在给定时刻请求数据(通过对 read() 或类似函数的调用)并不重要: 只要设备文件打开并且 FIFO中有数据,数据流就会继续。
这意味着主机无法从 FPGA 控制数据 flow (除非打开和关闭设备文件,或采用特定于应用程序的解决方案)。但是,在大多数实际的数据采集应用中,不需要控制数据流: 打开设备文件后数据流就开始了,这很好。从 FIFO读取每个数据元素的具体时间并不重要。
行为类似的设备文件称为异步数据流 (在 Xillybus的术语中)。
但是,在其他应用中,收集数据的时间很重要。例如, FPGA 上的应用逻辑可能会从 FIFO发送 status 寄存器而不是数据的内容。这在演示包的中进行了演示,其中设备文件名为 xillybus_mem_8。在这种情况下,控制何时在 FPGA收集数据非常重要: 主机读取设备文件以获取有关当时状态的信息,而不是过去某个未知时间的状态。
Xillybus 有 synchronous streams 用于此类应用程序: IP core 总是从 FPGA收集尽可能少的数据。换句话说, IP core 仅在响应主机上对 read() (或类似)的函数调用时收集数据。因此,主机控制何时从 FPGA收集数据。
同步数据流的缺点是数据流中存在暂停。这些暂停的主要问题是,当数据流暂时停止时, FPGA 上的 FIFO 可能会变满。这些暂停还会降低数据流的效率,因此最大传输速率会降低。但是,这两个缺点仅与数据采集应用程序有关。这样的应用程序无论如何都应该使用异步数据流。
关于反方向的设备文件,异步数据流和同步数据流也有区别。在这个方向上,区别在于 write() 函数调用的返回: 对于异步数据流,一旦将数据写入 RAM 缓冲区, write() 就会返回。所以在大多数情况下, write() 根本不休眠。另一方面,对于同步数据流, write() 会等到数据在 FPGA上交付。当使用通信通道发送命令时,这一点很重要。但再一次,这对数据采集应用程序不利。
在演示包的中,只有 /dev/xillybus_mem_8 是同步数据流。其他四个设备文件(device files)是异步数据流。
在IP Core Factory中,选择同步数据流还是异步数据流取决于应用程序的选择( drop-down menu 为“use”)。例如,如果您选择“数据 acquisition / playback(Data acquisition / playback)”,该工具将生成一个异步数据流(asynchronous streams)。如果您选择“Command and status”,您将获得同步数据流。也可以通过关闭“Autoset internals”来手动选择它。
有关异步数据流和同步数据流的更多信息,请参阅 programming guide for Linux (或programming guide for Windows )中的第 2 部分。关于 IP Core Factory,请参考 guide to defining a custom Xillybus IP core。
概括
可以使用 Xillybus简单快速地创建简单且实用的数据采集系统(data acquisition system): 应用软件归结为使用标准 Linux 命令(“cat”)。在 FPGA方面,与 Xillybus的 IP core 的交互仅包括将数据写入 FIFO。
使用 Xillybus 收集的数据保证无错误且连续。但是,由于操作系统的性质,无法保证永远不会出现溢出。由于这是不可避免的,因此最佳方法是保证在发生这种情况时检测到溢出。 Xillybus 通过向主机发送 EOF 来为此目的提供一种简单的机制。