本页是介绍 Multi-Gigabit Transceiver (MGT)系列的第四页。前几页讨论了 MGT 和与之一起使用的一些协议(protocols) ,以及一些编码方法。
介绍
正如本系列第一页所述, MGT 只是一种复杂的 SERDES。使其变得复杂的原因之一是 MGT 内部有一些构建块,有助于实现某些特定的协议。本页解释了其中一些构建块背后的原理。
MGT 中包含这些单元的部分通常称为 PCS (Physical Coding Sublayer)。这个名称容易引起误解,因为 PCS 中的一些逻辑与编码和解码都无关。
这是典型 MGT的框图,显示了 PCS在更大范围内的位置。
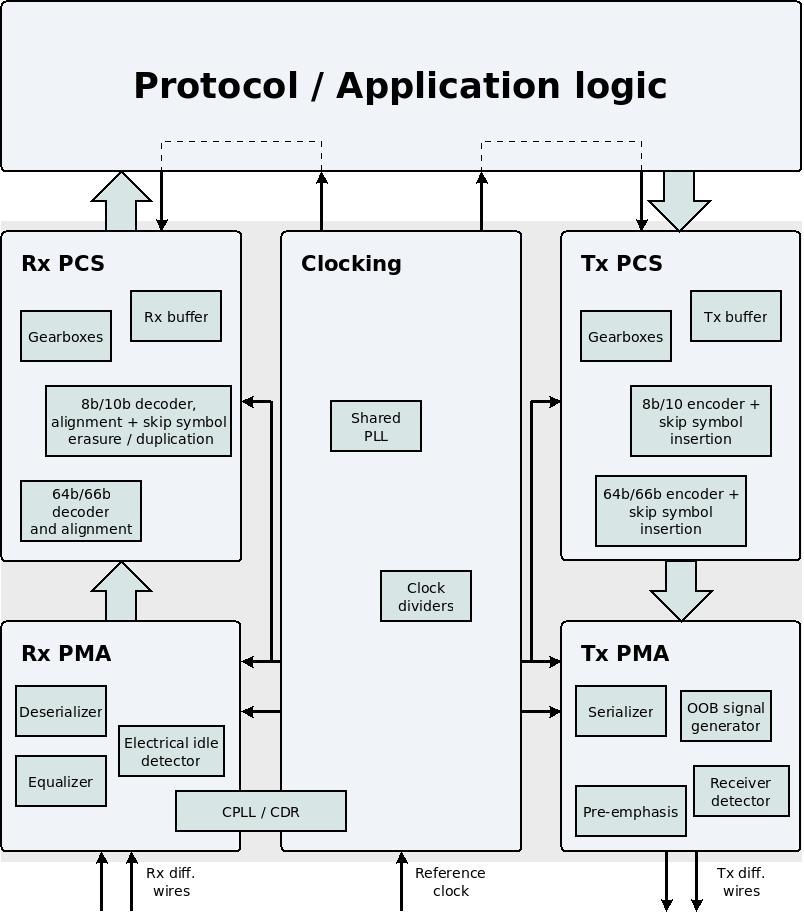
PCS 包括 PMA 和应用逻辑(user application logic)之间的所有内容。我将使用表达式 Tx PMA 和 Tx PCS 来表示 MGT 中用于传输数据的部分。同样, Rx PMA 和 Rx PCS 将是用于接收数据的部分的表达式。
Tx PCS 从输入端口开始,应用逻辑将数据传输给 MGT。当由比特(bits)组成的并行字已准备好通过物理线路传输时, Tx PCS 结束其角色。此并行字被交给 Tx PMA 部分,以便进行序列化并转换为电信号。
同样, Rx PCS 从 Rx PMA 接收并反序列化的并行数据字开始,到输出端口(output ports)结束,在此 MGT 将数据交给应用逻辑。
由于 PCS 由仅处理并行字的逻辑构成,显然 PCS的所有功能都可以在逻辑阵列(logic fabric)中实现。然而,出于与许多构建模块在 hard IPs中实现相同的原因,逻辑被集成到 MGT 中。一些协议利用了 PCS的编码功能。其他协议(例如xillyp2p )则依赖于它们自身的数据流处理方法,这使得 MGT 的使用更加简便,如本设计示例所示。
由于每 MGT 的内部结构都不同,因此无法以涵盖所有 MGTs的方式描述 MGT的 PCS 内部的详细数据流。因此,下面的描述和解释将重点介绍 PCS的功能块旨在实现的功能。 PCS 及其构建块的详细描述只能在 MGT自己的文档中找到。有了下面的解释,阅读本文档将变得更加容易。
编码和解码
上一页介绍了几种编码方法: 8b/10b、 64b/66b、 64b/67b、 128b/130b 和 128b/132b。
8b/10b 的实现是所有 FPGA MGTs的一部分,位于其 PCS内部。该实现包括将 8 位字编码和解码为 10 位字以及反之亦然,以及上一页中提到的其他功能: K-symbols,响应 comma symbol (K28.5)进行同步和对齐,并且还响应 skip symbols (K28.0)。
至于其他编码方法,每 MGT 都实现了一组不同的编码。 MGTs 在实现的编码功能方面也有所不同。有时 MGT的 PCS 只实现了所需的位宽转换器,有时还包括自动同步机制。没有标准的功能集。
位宽转换器
在整 PCS 以及与应用逻辑的接口中,物理通道上的数据流用并行字表示。当数据经过 PCS内部的不同处理步骤时,此并行字的宽度可能会发生变化。例如,当数据通过 8b/10b 编码器时,字宽从 8 位变为 10 位。
但是,用于向 MGT 传输应用数据的接口由输入端口和输出端口组成,其宽度始终是 8 的倍数。通常,该宽度是 16、 32、 40、 64、 80、 128 或 160 比特之一。
但是,如果使用 64b/66b 编码会发生什么情况?使用这种编码,物理通道上的数据流由长度为 66 比特的段组成。如果这些数据以 64 比特宽的并行字呈现,则每个段的开头每次都会出现在该字的不同位置。在允许的应用逻辑接口宽度中,没有一个可以避免这个问题。
这就是位宽转换器的作用。逻辑模块将到达其输入端口的数据重新组织为具有不同宽度的并行字。
例如,假设我们想要借助 MGT传输已使用 64b/66b 编码的数据,而编码器是在应用逻辑中实现的。编码器的输出(output)是 66 比特宽,但 MGT的输入可以是 64 或 80 比特宽(或者其他更不相关的替代方案)。为了解决这个问题,我们需要实现一个位宽转换器(gearbox),将现有的并行字(66 比特宽)重新组织为 MGT 可以接受的字(64 比特宽)。最好避免这种情况。
因此, MGTs 通常在其 PCS 部分中包含一个或多个位宽转换器。特别是,当 MGT 包含 64b/66b 编码器(或类似的编码器,例如 128b/130b)时, MGT内部也会有一个合适的位宽转换器。这样, MGT 就可以处理传输编码数据所需的所有任务: 首先用 MGT的编码器对数据进行编码,然后位宽转换器改变并行字的宽度,以便将该字交给 Tx PMA 部分进行传输。接收数据也采用类似的解决方案。
由于位宽转换器两侧的字数不同,因此进入位宽转换器的比特数量与离开位宽转换器的比特数量不同。如果输入的并行字数较宽,则位宽转换器必须偶尔拒绝接收字以进行补偿。同样,如果输出的并行字数较宽,则位宽转换器的输出端口上不会始终有有效内容。因此,如果位宽转换器仅使用一个时钟进行操作,则还必须有一个流控制信号来补偿两侧比特数量的差异。在 Xilinx / AMD的术语中,这称为同步位宽转换器(synchronous gearbox)。
或者,位宽转换器可以依赖于两个时钟。选择这些时钟中的频率以补偿位宽转换器两侧的字宽比。这种方法的优点是数据流永远不会在位宽转换器的任何一侧停止。但是,这种位宽转换器需要两个时钟并在两个时钟域(clock domains)中运行。这种解决方案称为异步位宽转换器(asynchronous gearbox)。
Tx buffer (Tx FIFO)
Tx buffer (通常称为 Tx FIFO)是 Tx PCS内部的小型 FIFO 。此 FIFO的深度通常为 16 或 32 个数据元素,在正常工作条件下通常为半满。此 FIFO 的必要性有些复杂,下面将进行说明。但是,此说明并不能回答配置 MGT时通常相关的唯一问题: 是否应启用 Tx buffer ?
答案是,在大多数情况下,应该启用 Tx buffer 。避免使用 Tx buffer 的唯一原因是如果它的延迟导致问题: 使用 Tx buffer 意味着并行字移交给 MGT 和该字在物理层上传输之间的延迟是未知的。在大多数应用中,这意味着不确定性约为或小于 0.1μs,因此协议不受此延迟影响。
至于为什么需要这 FIFO ,解释如下。
Tx PCS内部至少有两个时钟域: 第一个时钟用于与应用逻辑接口。第二个时钟(有时称为 XCLK)用于 Tx PCS 将并行字移交给 Tx PMA进行传输。
关于 MGT 内部的时钟主题在另一页上单独讨论。现在,了解为什么必须有两个独立的时钟就足够了。为了解释这一点,我们将 MGT 与常规 SERDES进行比较。
例如,假设我们想借助常规输出引脚(output pin)以 1000 Mbits/s 的速率传输数据。如今,大多数 FPGAs 都为此目的将 SERDES 连接到每个输出引脚(output pin)。在此示例中,我们假设应用逻辑向 SERDES 提供宽度为 8 比特的并行字。因此,此并行字的时钟为 125 MHz。
因此, SERDES 由两个时钟供电: 一个 125 MHz 时钟,第二个时钟,以及频率和 500 MHz。 SERDES 同时使用时钟边沿(clock edges)和 500 MHz 时钟,因此数据以 1000 MHz的期望速率传输。
SERDES 接收的两个时钟必须对齐。例如, 500 MHz 时钟的上升沿(rising edge)必须与 125 MHz 时钟的上升沿同时发生。这对于 SERDES的正常运行是必要的。这种对齐是通过使用一个锁相环(PLL)创建两个时钟,并使用具有相同传播延迟(propagation delay)的 clock buffers 来实现的。这是确保时钟对齐的常用方法: 参见相关时钟的解释。
但是如果我们要传输 5000 bits/s怎么办?这对于常规的输出引脚来说太多了,因此需要 MGT 。 MGT 内部还有一 SERDES 。我们假设进入这 SERDES 的并行字的宽度为 32 比特。因此,与此字关联的时钟的频率为 156.25 MHz。我们还假设与应用逻辑的接口由一个宽度也是 32 比特的并行字组成。因此,此接口的时钟频率也是 156.25 MHz 。但它是同一个时钟信号吗?
为了传输并行字, MGT的 SERDES 必须连接到 2500 MHz 时钟(新的比特在两个时钟边沿(clock edges)上传输)。这个频率对于 FPGA的通用锁相环(PLLs)来说太高了。也不可能将 FPGA的 clock buffers 或其他布线资源(routing resources)用于这个时钟。因此, MGT 必须有自己的锁相环和线(wires),以便生成 SERDES 所需的两个对齐的时钟。有关此内容的更多详细信息,请参阅有关 MGT的时钟的页面。
现在我们可以理解为什么 Tx PCS内部至少有两个时钟域。在此示例中, Tx PCS 为 Tx PMA 提供一个宽度为 32 比特的并行字。该字的时钟是 156.25 MHz。此时钟由 MGT的锁相环创建,以确保与 2500 MHz 时钟对齐。应用逻辑和 MGT 之间的接口基于完全相同的时钟频率,但尽管如此,应用逻辑仍不能使用相同的时钟信号: 应用逻辑的时钟必须经过 logic fabric的 clock buffer ,这样这个时钟才能到达所有逻辑单元(logic elements),而不需要任何偏移(skew)。由于这 clock buffer的延迟,应用逻辑的时钟无法自然地与 2500 MHz 时钟对齐。
对于跨时钟域(clock domain crossing),最直接的方法是使用 FIFO (如讨论此主题的页面中所述)。 Tx buffer 就是这 FIFO。
MGT提供了绕过 Tx buffer的选项,也提供了其他方法来确保时钟和 Tx PCS之间必要的对齐。但是,这些方法很复杂,而且容易出错。
Rx buffer (Rx FIFO)
Rx buffer (通常称为 Rx FIFO)是 Rx PCS内部的小型 FIFO 。原则上,此 buffer 与 Tx buffer相同,因此上述有关 Tx buffer 的所有内容也适用于 Rx buffer 。具体而言,对于是否应启用此 buffer 的答案是相同的: 在大多数应用程序中都应启用 Rx buffer ,除非它引起的延迟是不可接受的。
然而, Rx buffer 还有另外一个用途: 它允许 Rx PCS 与两个时钟一起工作,而这两个时钟之间的频率略有不同。现在我们来看看为什么会出现这种差异。
首先,让我们提醒自己,本讨论的重点是 MGT 接收数据流的部分。但是,此数据流是由另一 MGT生成的,而后者依赖于另一个参考时钟(reference clock)(在大多数情况下)。接收数据流的 MGT 通常无法访问发送器使用的时钟。相反,接收器仅根据数据流创建此时钟的副本(这称为CDR, Clock Data Recovery )。
因此, Rx PMA 可与时钟配合使用,后者可适应发射器的数据速率。频率和时钟之间不确定,但处于定义的公差范围内。协议始终定义频率允许偏离指定数字的程度,但始终存在一定程度的不确定性。
因此,从 Rx PMA 到 Rx PCS 的并行字交接接口取决于与发送器适配的时钟。 Rx PCS 必须与外部时钟同步。
但是为什么这与 Tx PCS不同呢?回想一下关于 Tx buffer 的讨论, Tx PCS的部分里面有 two 时钟域。尽管这两个时钟不是相同的时钟信号,但它们具有完全相同的频率,因为它们基于相同的参考时钟(reference clock)。
同样, Rx PCS的部分有两个时钟域。其中一个时钟有一个未知的频率。另一个时钟怎么样?答案是,这取决于应用逻辑的要求: 在大多数情况下, MGT 用于实现双向协议。该协议涉及响应收到的数据而传输数据。因此,所有应用逻辑与一个时钟同步会很方便。更具体地说,最常见的解决方案是所有应用逻辑与用于传输的时钟同步。这意味着 Rx PCS 和应用逻辑之间的接口与 Tx PCS相同的时钟同步。
采用这种方法时, Rx PCS 内的两个时钟不具有相同的频率。因此, Rx PCS 从 Rx PMA 接收数据的速率与将数据传递给应用逻辑的速率不同。 Rx buffer 能够暂时吸收这种差异: 如果应用逻辑取数据的速度比较慢, Rx buffer 就会把多余的数据积累起来,如果应用逻辑取数据的速度比较快, Rx buffer 就会逐渐清空。
当然,这只是一个临时的解决方案。除非采取措施将其填充水平维持在其容量的一半左右,否则 Rx buffer 迟早会溢出或变空。为此,有不同的机制。例如,回想一下上一页,如果使用 8b/10b 编码,则可以插入 skip symbols 以补偿时钟频率之间的差异。利用 skip symbols 的机制是在 Rx PCS内部实现的: 如果 Rx buffer 已满一半以上, Rx PCS 就不会将 skip symbols 写入 Rx buffer。这样会降低填充级别。另一方面,如果 Rx buffer 未满一半, Rx PCS 会反复从 Rx buffer 读取 skip symbols 。因此,新数据会填充 buffer ,同时缓冲区不会耗尽。因此, Rx buffer的填充级别会增加。
Rx buffer 通常被称为elastic buffer,因为它具有暂时吸收填充水平差异的能力。需要注意的是,这种能力并不总是需要的: 如果应用逻辑与 Rx PCS 接口,并且时钟的频率与 Rx PMA的时钟相同,则 Rx buffer 的行为原则上与 Tx buffer相同。采用这种方法时,如果需要,应用逻辑将负责实现跨时钟域。这种方法还允许在必要时禁用 Rx buffer (尤其为了避免延迟)。Xillyp2p是应用逻辑的一个示例,它使用 Rx PMA的时钟接收数据,但允许使用 Rx buffer 来简化时钟。
与 pseudo-random 顺序相关的功能
pseudo-random bit sequence (PRBS)是比特序列,看似随机,但实际上并非随机: PRBS 周期性地重复自身。由于很容易生成周期非常长的 PRBS (几百万个比特(bits)),因此 PRBS 的统计特性类似于真正随机的比特序列。
生成 PRBS 的最常见方法是借助 Linear-Feedback Shift Register (LFSR)。此逻辑由几个触发器(flip-flops)和异或门(XOR gates)组成,因此 LFSR 不需要大量资源即可实现。在讨论与 LFSRs相关的数学主题的单独页面中可以找到常用 LFSR 的示例。
MGT 中的 PCS 部分通常具有一些与 PRBS相关的功能。特别是, MGT 可能具有针对 scrambler的实现。当在 Rx PCS中实现 scrambler 的同步时,这可以节省大量工作。
PRBS 的另一个非常常见的用途是测试物理通道中的错误。这是一种非常有用的方法,因为接收器可以借助 LFSR轻松生成正确的比特序列。通过将本地生成的比特顺序(bit sequence)与到达的数据流进行比较,可以检测物理通道中的错误。这种机制在逻辑阵列中实现并不困难,但有些 MGTs 仍然内置了此功能。
遗憾的是,在使用 PRBS进行错误测试时,物理信道无法用于数据传输。因此,无法在信道实际使用时监控其质量。部分协议具备错误报告机制,但通常只有在错误中断数据传输时才会报告。xillyp2p是个例外,它还会报告链路空闲时发生的错误。
至此,本系列关于 MGTs的第四页就结束了。下一页将开始讨论 PMA 及其补偿困难物理通道的能力,以及其执行 eye scanning的能力。