이 페이지는 Multi-Gigabit Transceiver (MGT)를 소개하는 일련의 페이지 중 네 번째입니다. 이전 페이지에서는 MGT 와 함께 사용되는 몇 가지 protocols , 그리고 몇 가지 인코딩 방법에 대해 설명했습니다.
소개
이 시리즈의 첫 번째 페이지 에서 이미 언급했듯이, MGT는 단지 정교한 종류의 SERDES일 뿐입니다. 정교하게 만든 이유 중 하나는 MGT 내부에 몇 가지 빌딩 블록이 있어서 특정 protocols를 구현하는 데 도움이 됩니다. 이 페이지에서는 이러한 빌딩 블록 중 일부의 근거를 설명합니다.
이러한 유닛을 포함하는 MGT 의 부분은 일반적으로 PCS (Physical Coding Sublayer)라고 합니다. 이 이름은 오해의 소지가 있는데, PCS 내부의 일부 logic은 인코딩이나 디코딩과 아무 관련이 없기 때문입니다.
이는 일반적인 MGT의 블록 다이어그램으로, 더 큰 맥락에서 PCS의 위치를 보여줍니다.
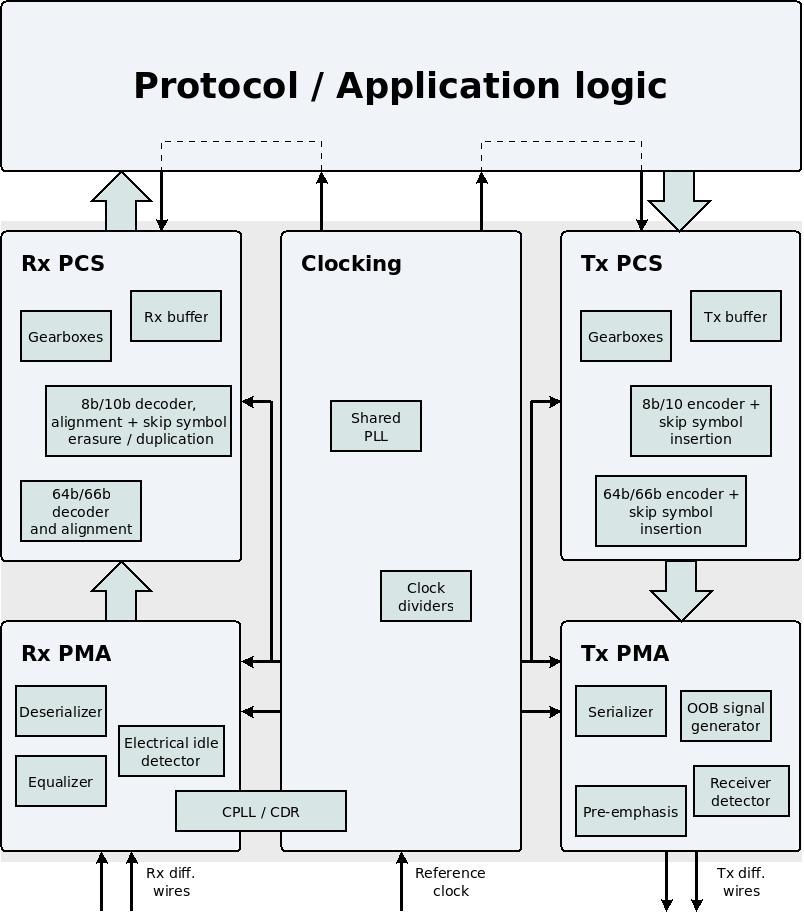
PCS는 PMA 와 user application logic사이의 모든 것으로 구성됩니다. MGT 에서 데이터 전송에 사용되는 부분에 대해 Tx PMA 와 Tx PCS 라는 표현을 사용하겠습니다. 마찬가지로 Rx PMA 와 Rx PCS는 데이터 수신에 사용되는 부분에 대한 표현이 될 것입니다.
Tx PCS는 application logic이 MGT로 전송할 데이터를 넘기는 input ports 에서 시작합니다. Tx PCS는 물리적 와이어를 통해 전송할 준비가 된 bits 로 구성된 병렬 단어가 있을 때 역할을 끝냅니다. 이 병렬 단어는 직렬화 및 전기 신호로 변환하는 목적으로 Tx PMA 부분에 넘깁니다.
마찬가지로, Rx PCS는 Rx PMA가 수신하여 역직렬화한 병렬 데이터 단어로 시작하여 MGT가 application logic에 데이터를 전달하는 output ports 에서 끝납니다.
PCS는 병렬 워드에서만 동작하는 logic 로 구성되어 있으므로 PCS의 모든 기능을 logic fabric에 구현할 수 있음이 분명합니다. 그럼에도 불구하고, 이 logic은 많은 구성 요소가 hard IPs에 구현된 것과 같은 이유로 MGT 내부에 구현됩니다. 일부 protocols는 PCS의 인코딩 기능을 활용합니다. 다른 protocols (예: xillyp2p )는 데이터 스트림을 처리하기 위해 자체 메서드를 사용하므로 이 설계 예제 에서 볼 수 있듯이 MGT 사용이 훨씬 간편합니다.
각 MGT는 내부 구조가 다르기 때문에 MGT의 PCS 내부의 자세한 데이터 흐름을 모든 MGTs를 포괄하는 방식으로 설명하는 것은 불가능합니다. 따라서 아래의 설명과 설명은 PCS의 기능 블록이 달성하려는 것에 초점을 맞춥니다. PCS 와 그 구성 요소에 대한 자세한 설명은 MGT의 자체 설명서에서만 찾을 수 있습니다. 아래의 설명을 통해 이 설명서를 읽는 것이 더 쉬워지기를 바랍니다.
인코딩 및 디코딩
이전 페이지 에서는 여러 가지 인코딩 방법이 소개되었습니다. 8b/10b, 64b/66b, 64b/67b, 128b/130b 및 128b/132b.
8b/10b 의 구현은 모든 FPGA MGTs의 일부이며, PCS내부에 있습니다. 구현에는 8비트 단어를 10비트 단어로 인코딩 및 디코딩하는 것과 그 반대의 작업이 포함되며, 이전 페이지 에서 언급한 다른 기능도 포함됩니다. K-symbols는 comma symbol (K28.5)에 대한 응답으로 동기화 및 정렬을 하며 skip symbols (K28.0)에도 응답합니다.
다른 인코딩 방법과 마찬가지로 각 MGT는 다른 인코딩 세트를 구현합니다. MGTs 도 인코딩의 어떤 기능이 구현되는지 다릅니다. 때로는 MGT의 PCS가 필요한 gearbox만 구현하고, 때로는 자동 동기화 메커니즘도 포함됩니다. 표준 기능 세트는 없습니다.
Gearboxes
PCS 전체와 application logic와의 인터페이스에서 물리적 채널의 데이터 스트림은 병렬 단어로 표현됩니다. 이 병렬 단어의 너비는 데이터가 PCS내부의 여러 처리 단계를 거치면서 변경될 수 있습니다. 예를 들어, 데이터가 8b/10b 인코더를 통과하면 단어 너비가 8비트에서 10비트로 변경됩니다.
그러나 MGT 와 애플리케이션 데이터를 주고받기 위한 인터페이스는 항상 8의 배수인 폭을 갖는 input ports 와 output ports 로 구성됩니다. 일반적으로 이 폭은 16, 32, 40, 64, 80, 128 또는 160 bits중 하나입니다.
하지만 예를 들어 64b/66b 인코딩을 사용하면 어떻게 될까요? 이 인코딩을 사용하면 물리적 채널의 데이터 스트림은 각각 66 bits 길이의 세그먼트로 구성됩니다. 이 데이터가 64 bits 너비의 병렬 단어로 표시되면 각 세그먼트의 시작은 매번 이 단어의 다른 위치에 나타납니다. application logic와의 인터페이스에 허용되는 너비 중 어느 것도 이 문제를 피할 수 없습니다.
이것이 바로 gearbox 의 역할입니다. input port 에 도착한 데이터를 다른 폭의 병렬 단어로 재구성하는 logic module 입니다.
예를 들어, MGT의 도움으로 64b/66b 로 인코딩된 데이터를 전송하고, 인코더가 application logic에 구현되어 있다고 가정해 보겠습니다. 인코더의 output은 66 bits 폭이지만, MGT의 input은 64 또는 80 bits 폭(또는 훨씬 덜 관련성이 있는 다른 대안)이 될 수 있습니다. 이를 해결하려면 기존 병렬 단어(66 bits 폭)를 MGT가 허용할 수 있는 단어(64 bits 폭)로 재구성하는 gearbox를 구현해야 합니다. 이는 피하는 것이 더 나은 상황입니다.
이러한 이유로 MGTs는 종종 PCS 부분에 하나 또는 여러 개의 gearboxes를 포함합니다. 특히 MGT 에 64b/66b 인코더(또는 128b/130b와 같은 유사한 인코더)가 포함된 경우 MGT내부에 적합한 gearbox 도 있습니다. 이런 방식으로 MGT는 인코딩된 데이터의 전송에 필요한 모든 작업을 처리합니다. 먼저, MGT의 인코더로 데이터를 인코딩한 다음, gearbox가 병렬 워드의 폭을 변경하여 이 워드를 Tx PMA 파트로 넘겨 전송합니다. 비슷한 솔루션이 데이터 수신에도 사용됩니다.
gearbox 의 양쪽에 있는 단어가 다르기 때문에 gearbox 에 들어가는 bits 의 수는 gearbox 에서 나가는 bits 의 수와 다릅니다. input의 병렬 단어가 더 넓으면 gearbox는 이를 보상하기 위해 가끔 단어를 수신하지 않아야 합니다. 마찬가지로 output의 병렬 단어가 더 넓으면 gearbox는 output port에 항상 유효한 것이 있는 것은 아닙니다. 따라서 gearbox가 하나의 clock로만 작동하는 경우 각 면에 있는 bits 의 다른 양을 보상하는 흐름 제어 신호도 있어야 합니다. Xilinx / AMD의 용어로는 이를 synchronous gearbox라고 합니다.
또는 gearbox는 두 개의 clocks에 의존할 수 있습니다. 이러한 clocks 의 frequencies는 gearbox의 양쪽에 있는 단어 폭의 비율을 보상하도록 선택됩니다. 이 방법의 장점은 gearbox의 어느 쪽에서도 데이터 흐름이 중단되지 않는다는 것입니다. 그러나 이러한 종류의 gearbox는 두 개의 clocks가 필요하고 두 개의 clock domains에서 작동합니다. 이 솔루션을 asynchronous gearbox라고 합니다.
Tx buffer (Tx FIFO)
Tx buffer (종종 Tx FIFO라고 함)는 Tx PCS내부의 작은 FIFO 입니다. 이 FIFO의 깊이는 일반적으로 16개 또는 32개 데이터 요소이며, 정상적인 작업 조건에서는 일반적으로 반만 채워집니다. 이 FIFO 의 필요성은 다소 복잡하며 아래에서 설명합니다. 그러나 이 설명은 MGT를 구성할 때 일반적으로 관련이 있는 유일한 질문에 대한 답은 아닙니다. Tx buffer를 활성화해야 할까요?
답은 대부분의 경우 Tx buffer를 활성화해야 한다는 것입니다. Tx buffer를 사용하지 않는 유일한 이유는 지연으로 인해 문제가 발생하는 경우입니다. Tx buffer를 사용하면 병렬 단어가 MGT 로 전달되는 순간과 이 단어가 물리 계층에서 전송되는 순간 사이에 알 수 없는 지연이 발생합니다. 대부분의 애플리케이션에서 이는 0.1μs보다 약 또는 그 이하의 불확실성을 의미하므로 protocol은 이 지연에 무관심합니다.
FIFO가 필요한 이유는 다음과 같습니다.
Tx PCS내부에는 최소 두 개의 clock domains가 있습니다. 첫 번째 clock은 application logic와 인터페이싱하는 데 사용됩니다. 두 번째 clock (때로는 XCLK라고 함)는 Tx PCS가 병렬 단어를 Tx PMA로 전송하는 데 사용됩니다.
MGT 내부의 clocking 에 대한 주제는 다른 페이지 에서 별도로 논의됩니다. 지금은 왜 두 개의 별도 clocks가 있어야 하는지 이해하는 것으로 충분합니다. 이를 설명하기 위해 MGT를 일반 SERDES와 비교하겠습니다.
예를 들어, 일반적인 output pin의 도움으로 1000 Mbits/s 속도로 데이터를 전송하고 싶다고 가정해 보겠습니다. 오늘날 대부분의 FPGAs는 이 목적을 위해 각 output pin 에 SERDES가 부착되어 있습니다. 이 예에서는 application logic이 SERDES 에 8 bits 너비의 병렬 단어를 공급한다고 가정해 보겠습니다. 따라서 이 병렬 단어의 clock은 125 MHz입니다.
따라서 SERDES 에는 두 개의 clocks가 공급됩니다. 한 개의 125 MHz clock, 그리고 두 번째 clock 와 frequency 또는 500 MHz. SERDES는 clock edges 와 500 MHz clock을 모두 사용하므로 데이터는 원하는 속도인 1000 MHz로 전송됩니다.
SERDES가 수신하는 두 개의 clocks는 정렬되어야 합니다. 예를 들어, 500 MHz clock 의 rising edge는 125 MHz clock의 rising edge 와 동시에 발생해야 합니다. 이는 SERDES의 적절한 작동에 필요합니다. 이 정렬은 하나의 PLL을 사용하여 두 개의 clocks를 생성하고 동일한 propagation delay을 갖는 clock buffers를 사용하여 달성됩니다. 이는 clocks가 정렬되도록 하는 일반적인 방법입니다. 관련된 clocks에 대한 설명을 보세요.
하지만 5000 bits/s를 전송하고 싶다면 어떨까요? 일반적인 output pin로는 너무 많으므로 MGT가 필요합니다. MGT 내부에도 SERDES가 있습니다. 이 SERDES 로 가는 병렬 워드의 너비가 32 bits라고 가정해 보겠습니다. 따라서 이 워드와 연관된 clock 의 frequency는 156.25 MHz입니다. 또한 application logic 와의 인터페이스가 너비가 32 bits 인 병렬 워드로 구성되어 있다고 가정해 보겠습니다. 따라서 이 인터페이스의 clock frequency 도 156.25 MHz 입니다. 하지만 같은 clock signal일까요?
병렬 단어를 전송하기 위해 MGT의 SERDES를 2500 MHz clock 에 연결해야 합니다(새로운 bit은 두 clock edges모두에서 전송됨). 이 frequency는 FPGA의 범용 PLLs에 비해 너무 높습니다. 이 clock에 FPGA의 clock buffers 나 다른 routing resources를 사용하는 것도 불가능합니다. 따라서 MGT는 SERDES 에 필요한 두 개의 정렬된 clocks를 생성하기 위해 자체 PLLs 와 wires를 가져야 합니다. 이에 대한 자세한 내용은 MGT의 clocking페이지를 참조하세요 .
이제 Tx PCS안에 최소 두 개의 clock domains가 있는 이유를 이해할 수 있는 입장에 있습니다. 이 예에서 Tx PCS는 32 bits 너비의 병렬 단어를 Tx PMA 에 공급합니다. 이 단어의 clock은 156.25 MHz입니다. 이 clock은 2500 MHz clock와의 정렬을 보장하기 위해 MGT의 PLL 에 의해 생성됩니다. application logic 와 MGT 간의 인터페이스는 정확히 동일한 clock frequency를 기반으로 하지만 application logic은 다음과 같은 사실에도 불구하고 동일한 clock signal을 사용할 수 없습니다. application logic의 clock은 logic fabric의 clock buffer를 거쳐야 이 clock이 skew없이 모든 logic elements 에 도달할 수 있습니다. 이 clock buffer의 지연으로 인해 application logic의 clock은 자연스럽게 2500 MHz clock와 정렬되지 않습니다.
clock domain crossing 의 가장 간단한 방법은 FIFO를 사용하는 것입니다( 이 주제를 논의하는 페이지 에 언급된 대로). Tx buffer는 이 FIFO입니다.
Tx buffer를 우회하는 옵션을 제공하는MGT는 Tx PCS내부의 clocks 사이에 필요한 정렬을 보장하기 위한 다른 방법도 제공합니다. 그러나 이러한 방법은 복잡하고 오류가 발생하기 쉽습니다.
Rx buffer (Rx FIFO)
Rx buffer (종종 Rx FIFO라고 함)는 Rx PCS내부의 작은 FIFO 입니다. 원칙적으로 이 buffer는 Tx buffer와 동일하므로 위에서 Tx buffer 에 대해 말한 모든 내용은 Rx buffer 에도 해당합니다. 특히 이 buffer를 활성화해야 하는지에 대한 답은 동일합니다. Rx buffer는 지연이 용납할 수 없는 경우를 제외하고 대부분의 애플리케이션에서 활성화해야 합니다.
하지만 Rx buffer 에는 추가적인 목적이 있습니다. 이를 통해 Rx PCS는 frequencies사이에 약간의 차이가 있는 두 개의 clocks 와 함께 작동할 수 있습니다. 이제 이러한 차이가 발생하는 이유를 살펴보겠습니다.
먼저, 이 논의는 데이터 스트림을 수신하는 MGT 부분에 초점을 맞추고 있다는 점을 상기해 보겠습니다. 그러나 이 데이터 스트림은 다른 MGT에 의해 생성되고, 이는 다른 reference clock (대부분의 시나리오에서)에 의존합니다. 데이터 스트림을 수신하는 MGT는 종종 송신기에서 사용하는 clock 에 액세스할 수 없습니다. 대신 수신기는 데이터 스트림에만 기반하여 이 clock 의 복제본을 만듭니다(이를 CDR, Clock Data Recovery 라고 합니다).
결과적으로 Rx PMA는 송신기의 데이터 속도에 적응하는 clock 와 함께 작동합니다. 이 clock 의 frequency는 정의된 허용 범위 내에서 불확실합니다. protocol은 항상 frequency가 지정된 숫자에서 얼마나 벗어날 수 있는지 정의하지만 항상 불확실성 수준이 있습니다.
따라서 Rx PMA 에서 Rx PCS 로 병렬 단어를 넘기기 위한 인터페이스는 송신기에 적응하는 clock 에 따라 달라집니다. Rx PCS는 외국 clock와 동기화되어야 합니다.
하지만 이게 Tx PCS와 다른 이유는 무엇일까요? Tx buffer 에 대한 논의에서 Tx PCS의 일부 안에 two clock domains가 있다는 것을 기억하세요. 이 두 개의 clocks가 동일한 clock signal은 아니지만, 동일한 reference clock을 기반으로 하기 때문에 정확히 동일한 frequency를 가지고 있습니다.
마찬가지로 Rx PCS부분에는 두 개의 clock domains가 있습니다. clocks 중 하나에는 알려지지 않은 frequency가 있습니다. 다른 clock은 어떨까요? 답은 application logic의 요구 사항에 따라 달라집니다. 대부분의 시나리오에서 MGT는 양방향 protocol을 구현하는 데 사용됩니다. 이 protocol은 수신된 데이터에 대한 응답으로 데이터를 전송하는 것을 포함합니다. 따라서 모든 application logic이 하나의 clock와 동기화되는 것이 편리합니다. 더 구체적으로, 가장 일반적인 솔루션은 모든 application logic이 전송에 사용되는 clock 와 동기화되는 것입니다. 즉, Rx PCS 와 application logic 간의 인터페이스는 Tx PCS와 동일한 clock 와 동기화됩니다.
이 접근 방식을 취하면 Rx PCS 내부의 두 clocks는 동일한 frequency를 갖지 않습니다. 결과적으로 Rx PCS는 Rx PMA 에서 데이터를 수신하는 속도와 이 데이터를 application logic로 전달하는 속도가 다릅니다. Rx buffer는 이 차이를 일시적으로 흡수할 수 있습니다. application logic이 더 느린 속도로 데이터를 가져오면 Rx buffer는 잉여를 축적합니다. application logic이 더 빠른 속도로 데이터를 가져오면 Rx buffer는 점차 비워집니다.
물론, 이것은 매우 일시적인 해결책입니다. Rx buffer는 조만간 오버플로되거나 비어 있게 될 것입니다. 채우기 수준을 용량의 절반 정도로 유지하기 위한 조치를 취하지 않는 한 말입니다. 이 목적을 위한 다양한 메커니즘이 있습니다. 예를 들어, 이전 페이지 에서 8b/10b 인코딩을 사용하는 경우 clock frequencies간의 차이를 보상하기 위해 skip symbols를 삽입할 수 있다는 것을 기억하세요. skip symbols를 활용하기 위한 메커니즘은 Rx PCS내부에 구현되어 있습니다. Rx buffer가 반 이상 채워지면 Rx PCS는 skip symbols를 Rx buffer에 쓰지 않습니다. 이렇게 하면 채우기 수준이 줄어듭니다. 반면 Rx buffer가 반 이하로 채워지면 Rx PCS는 Rx buffer 에서 skip symbols를 반복해서 읽습니다. 결과적으로 이 buffer가 비워지지 않는 동시에 새로운 데이터가 buffer를 채웁니다. 따라서 Rx buffer의 채우기 수준이 증가합니다.
Rx buffer는 종종 elastic buffer 라고 불리는데, 이는 채우기 수준의 차이를 일시적으로 흡수하는 기능 때문입니다. 이 기능이 항상 필요한 것은 아니라는 점에 유의하는 것이 중요합니다. application logic이 Rx PMA의 clock와 동일한 frequency를 가진 clock을 통해 Rx PCS 와 인터페이스하는 경우, Rx buffer는 원칙적으로 Tx buffer와 동일하게 동작합니다. 이 방식을 사용하면 필요한 경우 application logic이 clock domain crossing을 구현합니다. 또한 이 방식을 사용하면 필요한 경우 Rx buffer를 비활성화할 수 있습니다(특히 지연을 방지하기 위해). Xillyp2p 는 Rx PMA의 clock을 통해 데이터를 수신하지만 clocking을 단순화하기 위해 Rx buffer를 사용할 수 있는 application logic 의 한 예입니다.
pseudo-random sequences관련 기능
pseudo-random bit sequence (PRBS)는 무작위로 나타나는 bits 시퀀스이지만 실제로는 무작위가 아닙니다. PRBS는 주기적으로 반복됩니다. 매우 긴 주기(수백만 bits)로 PRBS를 생성하는 것이 쉽기 때문에 PRBS 의 통계적 속성은 진정으로 무작위적인 bits시퀀스와 유사합니다.
PRBS를 생성하는 가장 일반적인 방법은 Linear-Feedback Shift Register (LFSR)의 도움을 받는 것입니다. 이 logic은 몇 개의 flip-flops 와 XOR gates로 구성되어 있으므로 LFSR를 구현하는 데 많은 리소스가 필요하지 않습니다. 일반적으로 사용되는 LFSR 의 예는 LFSRs와 관련된 수학적 주제를 논의하는 별도 페이지 에서 찾을 수 있습니다.
MGT 의 PCS 부분은 일반적으로 PRBS와 관련된 몇 가지 기능을 가지고 있습니다. 특히, MGT는 scrambler에 대한 구현을 가질 수 있습니다. scrambler 의 동기화가 Rx PCS에 구현되면 많은 작업을 절약할 수 있습니다.
PRBS 의 또 다른 매우 일반적인 용도는 물리적 채널에서 오류를 테스트하는 것입니다. 이는 수신기가 LFSR의 도움으로 bits 의 올바른 시퀀스를 쉽게 생성할 수 있기 때문에 유용한 방법입니다. 물리적 채널의 오류는 로컬에서 생성된 bit sequence를 도착하는 데이터 스트림과 비교하여 감지합니다. 이 메커니즘은 logic fabric에서 구현하기 어렵지 않지만 일부 MGTs 에는 그럼에도 불구하고 이 기능이 내장되어 있습니다.
안타깝게도 PRBS를 사용하여 오류 테스트를 수행하는 동안에는 물리적 채널을 데이터 전송에 사용할 수 없습니다. 따라서 채널이 실제로 사용되는 동안 채널 품질을 모니터링하는 것은 불가능합니다. 일부 protocols는 오류 보고 메커니즘을 갖추고 있지만, 일반적으로 오류는 전송된 데이터가 중단된 경우에만 보고됩니다. 한 가지 예외는 xillyp2p 로, 링크가 유휴 상태일 때 발생하는 오류도 보고합니다.
이것으로 MGTs에 대한 이 시리즈 의 네 번째 페이지를 마무리합니다. 다음 페이지에서는 PMA 와 어려운 물리적 채널을 보상하는 능력, 그리고 eye scanning을 수행하는 능력에 대해 논의하기 시작합니다.