이 페이지는 Multi-Gigabit Transceiver (MGT)를 소개하는 일련의 페이지 중 일곱 번째이자 마지막 페이지입니다.
소개
FPGA의 MGT 구성 작업의 대부분이 데이터 처리와 올바른 protocol선택 과 관련이 있을 것이라고 기대하는 것은 당연합니다. 따라서 clocking을 올바르게 만드는 데 얼마나 많은 시간과 노력이 필요한지 놀랄 수 있습니다. 이러한 노력의 대부분은 일반적으로 MGT가 clock resources 와 관련하여 제공하는 다양한 옵션과 이러한 옵션이 부과하는 제한 사항을 정리하는 데 사용됩니다.
MGT의 clocks 와 관련된 설계 규칙은 각 FPGA에서 다르기 때문에 이 주제에 대한 정확하고 포괄적인 정보에 대한 유일한 신뢰할 수 있는 출처는 MGT의 자체 문서입니다. 이러한 문서는 일반적으로 메커니즘과 세부 정보에 초점을 맞추고 있으며 이러한 메커니즘이 필요한 이유를 설명하지 않을 수 있습니다. 이 페이지는 MGT에서 사용하는 clocks 와 관련된 개념과 과제를 논의하여 이러한 격차를 메우려고 시도합니다.
PLLs 및 VCOs
일반적으로 PLLs는 reference clock 의 frequency 에 상수를 곱합니다. 이 상수는 때때로 정수이지만, 분수일 수도 있고, 1보다 작을 수도 있습니다. 다시 말해, PLL의 output 에서 frequency는 reference clock의 frequency보다 낮을 수 있습니다. 이는 MGTs와 함께 사용되는 PLLs 에서는 거의 발생하지 않지만, logic fabric의 경우 PLLs 에서는 유용할 수 있습니다.
FPGA에는 MGTs에 필요한 clocks를 생성하기 위한 별도의 PLLs가 있습니다. logic fabric 에 속하는 PLLs 및 기타 clock resources는 MGT에 필요한 frequencies를 지원할 수 없습니다. 특히 MGT는 frequency가 데이터 속도의 최소 절반인 clock을 필요로 합니다. 낮은 데이터 속도의 경우 필요한 frequency가 더 높을 수 있습니다.
예를 들어, 데이터 속도가 5 Gb/s가 면 bit clock은 일반적으로 2.5 GHz에서 실행됩니다. 이는 MGT의 SERDES가 clock edges (DDR)에 의해 모두 활성화되기 때문입니다. 그러나 데이터 속도가 비교적 낮으면 MGT의 PLL 의 output이 더 낮은 frequency로 나뉘는 경우가 있습니다.
거의 모든 PLLs는 동일한 원리에 따라 작동합니다. 중앙 부분은 frequencies의 범위를 갖는 clock을 생성할 수 있는 VCO (Voltage Controlled Oscillator)입니다. VCO의 output은 frequency를 상수로 나누는 clock divider 에 삽입됩니다. clock divider 의 output은 PLL의 reference clock와 비교됩니다. 제어 메커니즘은 VCO의 frequency를 조정하여 reference clock 와 clock divider의 output이 정렬되도록 합니다. 즉, 이 두 개의 signals는 동일한 frequency 와 동일한 phase를 갖습니다.
5 Gb/s의 예로 돌아가서, reference clock의 frequency가 125 MHz라고 가정해 봅시다. PLL 에 대한 가능한 구현은 VCO의 output을 20로 나누는 것입니다. 나누어진 signal은 reference clock와 비교되고 정렬됩니다. 따라서 VCO의 frequency는 2500 MHz여야 합니다. 왜냐하면 2500 MHz / 20 = 125 MHz가 기 때문입니다.
clock을 생성하는 이 방법은 bits를 전송하는 데 적합합니다. 전송하는 MGT는 각 bit의 시간 주기가 시작되고 끝나는 곳을 혼자 결정합니다. 그러나 MGT가 bits를 수신하면 다른 쪽에서 각 bit의 타이밍을 지시합니다. 따라서 수신기는 도착하는 데이터 스트림에 적응해야 합니다. 이전 페이지 중 하나 에서 언급했듯이 이 적응 메커니즘을 Clock Data Recovery (CDR)라고 합니다. CDR 의 구현은 수신기의 clock을 도착하는 데이터 스트림에 동기화하기 위해 VCO의 frequency를 조정하는 control loop 로 구성됩니다. reference clock은 때때로 VCO를 예상 frequency에 충분히 가까운 초기 frequency 에 두는 데 사용됩니다. 동기화가 달성된 후 reference clock은 무시됩니다.
PLLs활용
FPGA 내부의 MGTs 용 PLLs는 복잡한 주제입니다. 각 MGT는 여러 개의 PLL에서 clock을 수신할 수 있습니다. FPGA 프로젝트에서 MGTs를 사용하는 애플리케이션이 하나뿐인 경우 tools는 일반적으로 가장 적합한 PLL을 자동으로 선택합니다. 그러나 MGTs가 프로젝트에서 다른 목적으로 사용되는 경우 각 MGT가 가장 적합한 PLL 에 연결되어 있는지 확인하는 것이 중요합니다.
FPGA에는 일반적으로 여러 MGTs가 공유하는 PLLs가 있습니다. AMD (Xilinx)는 이를 QPLL라고 부르고 Altera는 fPLL 와 ATX PLL을 갖습니다. 반면, 특정 MGT에 로컬인 PLLs가 있습니다. 이를 CPLL (AMD / Xilinx) 또는 CMU PLL (Altera)라고 합니다. 로컬 PLLs는 일반적으로 공유된 PLLs에 비해 품질이 낮고 기능이 적습니다. 차이점은 frequencies, jitter의 범위와 reference clock와 관련하여 선택할 수 있는 곱셈 비율이 될 수 있습니다.
각 FPGA 에는 PLLs 와 MGTs를 상호 연결하는 방법을 정의하는 복잡한 규칙 세트가 있습니다. 이러한 규칙은 또한 PLLs를 FPGA의 reference clock inputs에 연결하는 가능성을 정의합니다. 따라서 모든 MGTs를 필요한 clocks 에 연결할 수 있다고 당연하게 여길 수 없습니다. 이는 거의 제한이 없는 logic fabric의 clocks와는 매우 다릅니다.
따라서 각 MGT에 대해 어떤 PLL을 선택할지 결정하기 전에 datasheet을 주의 깊게 읽어보는 것이 좋습니다. 특히 PCB를 설계할 때 모든 MGTs 에 clocks를 제공할 수 있는지 확인하는 것이 중요합니다. 이는 필요한 모든 MGTs를 포함하는 FPGA 프로젝트를 만들고 이 프로젝트의 implementation이 성공하고 모든 pins가 올바른 위치에 배치되었는지 확인하여 수행할 수 있습니다.
Reference clock
FPGA 에는 MGTs의 PLLs를 위해 의도된 reference clocks를 위한 별도의 pins가 있습니다. PCB design에서 clock이 의도된 MGTs 와 함께 reference clock input을 사용할 수 있는지 확인하는 것이 중요합니다. reference clock inputs, PLLs 및 MGTs 간의 상호 연결은 모든 가능한 조합을 허용하지 않습니다. 허용되는 조합은 FPGA설명서에 설명되어 있지만 규칙이 복잡할 수 있으므로 확실한 결론에 도달하기 어려울 수 있습니다. FPGA 프로젝트의 도움을 받아 요구 사항이 충족되는지 확인하는 것이 더 나은 경우가 많습니다.
이 목적에 사용되는 clocks는 정확도 면에서 높은 품질과 낮은 jitter를 가져야 합니다. 범용 clock chip에서 생성된 clock을 연결하는 것은 일반적인 실수입니다. 그렇게 하면 MGT의 성능이 저하되고 신호 무결성 문제나 데이터 와이어에 추가된 노이즈처럼 보이는 오류가 발생할 수 있습니다.
MGT가 특정 protocol (예: PCIe, SuperSpeed USB 또는 SATA)용으로 의도된 경우 reference clock요구 사항에 대한 FPGA 제조업체의 설명서를 읽는 것이 좋습니다. "low-jitter clock source"로 표시된 여러 전자 부품은 충분하지 않을 수 있습니다.
Jitter는 무작위 프로세스입니다. jitter의 크기는 중요한 매개변수이지만 항상 충분한 것은 아닙니다. clock의 jitter 의 무작위성은 clock cycle에서 빠른 변화를 일으킬 수 있으며, 이러한 변화는 느릴 수도 있습니다. 이와 관련하여 jitter가 어떻게 작동하는지는 jitter의 noise spectrum에서 추론할 수 있습니다.
clock을 생성하는 구성 요소의 datasheet은 때때로 jitter 의 크기에 대한 숫자만 제공합니다(일반적으로 picoseconds로 측정). jitter의 noise spectrum 에 대한 정보는 종종 사용할 수 없습니다. 특히 jitter의 크기가 어쨌든 매우 낮은 경우 이러한 정보가 없음에도 불구하고 그러한 구성 요소가 적절할 수 있습니다. 이 질문에 대한 간단한 답은 종종 없습니다.
그럼에도 불구하고 reference clock의 품질은 MGT를 사용하는 모든 경우에 중요합니다. 잘 알려진 protocols의 요구 사항은 모든 프로젝트에서 사용할 수 있는 좋은 참고 자료입니다. development boards에서 reference clocks 로 사용되는 구성 요소와 비교하는 것도 유용합니다.
logic fabric을 위한Clocks
MGT 와 logic fabric 사이의 인터페이스에 사용되는 clock은 MGT자체의 PLL에서 유래되었습니다. 이는 PMA 내부에서 SERDES가 두 개의 clocks에 의존하기 때문에 필요합니다. 물리적 채널에서 bits 에 대응하는 clock 와 병렬 단어와 함께 사용되는 clock . SERDES가 제대로 작동하려면 이 두 개의 clocks가 PMA내부에 정렬되어야 합니다.
반면, logic fabric 에서 사용하는 모든 clock은 낮은 clock skew를 보장하는 방식으로 분산되어야 합니다. tools는 이 목적을 위해 종종 global clock buffer를 선택합니다. clock buffer 에서 모든 logic elements 까지의 propagation delay은 거의 동일하므로 clock의 edges는 모든 목적지에 동시에 도착합니다. 이는 tools가 logic fabric와 관련하여 적절한 timing 계산을 수행할 수 있도록 하는 데 필요한 조건입니다.
이 propagation delay이 모든 wires에 걸쳐 균일하더라도 반드시 작은 것은 아닙니다. 반대로 clock buffer를 목적지에 연결하는 FPGA 내부의 wires는 상당한 delay을 추가합니다. 이는 일반적으로 중요하지 않습니다. 이 모든 연결 간의 차이가 작기 때문입니다.
하지만 이 delay은 PMA 에서 사용하는 두 개의 clocks를 logic fabric의 clock와 정렬되지 않게 만듭니다. logic fabric의 리소스의 도움으로 이 세 개의 clocks를 정렬하는 것은 불가능합니다. 이 clocks 중 하나에 너무 높은 frequency가 있기 때문입니다. 그런데도 MGT 와 logic fabric은 양쪽이 동기화되는 clock이 있어야 합니다. 유일한 해결책은 다른 clock signal을 추가하는 것입니다.
이는 각 방향에 대해 최소 3개의 clock signals가 필요하다는 것을 의미합니다.
- 물리 채널에서 bits 와 동기화된 clock . 이 clock의 frequency는 종종 데이터 속도의 절반입니다(위의 예에서2.5 GHz ).
- PMA내부의 병렬 워드와 동기되는 clock . 이 clock은 때때로 XCLK라고도 합니다. 예를 들어, PMA가 32 bits 폭의 병렬 워드로 PCS 와 인터페이스하는 경우, 이 clock은 156.25 MHz 입니다( 5000 / 32 = 156.25가 기 때문입니다).
- logic fabric의 clock: 이것은 MGT 와 logic fabric사이의 인터페이스와 함께 사용되는 clock 입니다. 이 clock은 일반적으로 TXUSRCLK2, RXUSRCLK2, tx_coreclkin, rx_coreclkin 및 기타 유사한 이름(아래 다이어그램의 "Tx user clock" 및 "Rx user clock")과 같은 이름을 갖습니다. 이 clock의 frequency는 logic fabric와 인터페이스하는 데 사용되는 병렬 단어의 너비에 따라 달라집니다.
일반적으로 전송 및 수신을 위한 별도의 clocks가 있다는 점에 유의하세요. 이 블록 다이어그램은 MGT내부의 clocks 의 일반적인 분포를 보여줍니다.
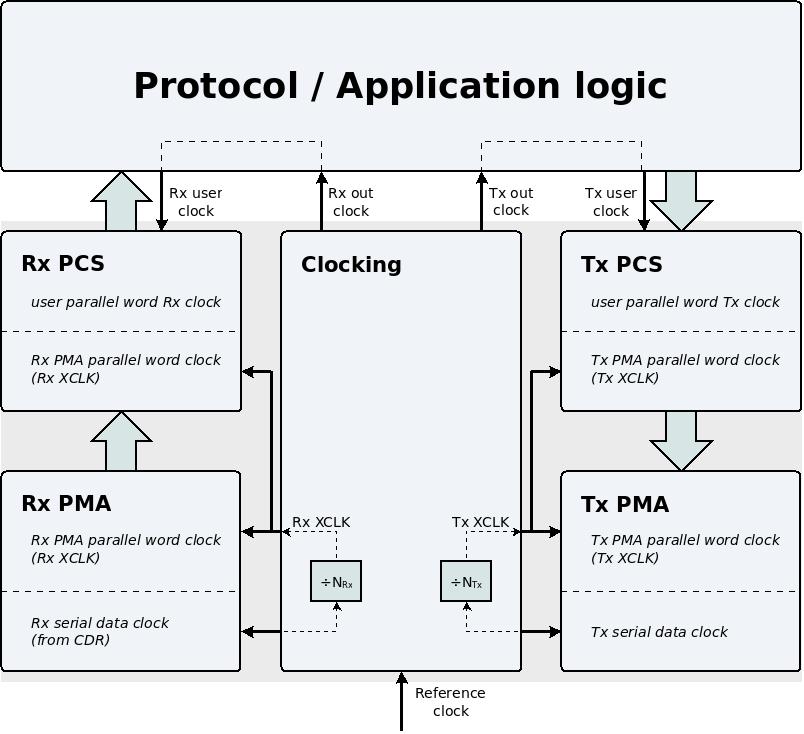
이 블록 다이어그램에는 위에서 언급한 3개가 아닌 각 방향에 대해 4개의 clocks가 있습니다. 다음에 설명합니다.
logic fabric의 clock생성
위에서 설명한 대로, logic fabric 와 MGT 에 공통인 clock은 logic fabric의 clock buffer와 함께 배포되어야 합니다. 반면, 이 clock은 MGT내부에서 시작되어야 합니다.
우리는 이 두 가지 상충되는 요구 사항에 대한 가장 간단한 해결책부터 시작하겠습니다. MGT는 실제로 clock을 생성하여 output port에서 사용할 수 있게 합니다. 이 output port는 일반적으로 TXOUTCLK, RXOUTCLK, tx_clkout, rx_clkout 등으로 불립니다(위의 다이어그램에서 "Tx out clock"와 "Rx out clock"로 명명된 네 번째 clock입니다). 이 signal은 logic fabric clock buffer의 input 로 들어갑니다. 이 clock buffer 의 output은 MGT 와 logic fabric사이의 인터페이싱에 사용되는 clock signal 입니다.
이러한 배열의 결과로, logic fabric의 clock 와 MGT 에서 생성된 clock 사이의 유일한 차이점은 clock buffer의 propagation delay 입니다. 다시 말해, MGT는 phase를 제외하고 logic fabric의 clock을 완전히 제어합니다. 이는 특히 CDR의 clock이 logic fabric 와의 인터페이스의 기반으로 사용되는 경우 데이터를 수신하는 데 중요합니다(이 옵션은 아래에서 설명합니다). 이는 CDR가 도착하는 데이터 스트림과 동기화를 유지하기 위해 이 clock의 frequency를 지속적으로 조정하기 때문입니다.
이전 페이지 에서 논의했듯이, PCS는 logic fabric의 clock 와 PMA의 clock의 phases 간의 차이를 극복하기 위한 메커니즘을 제공합니다. Tx buffer 또는 Rx buffer가 가장 쉬운 선택이지만, PCS 도 이 차이를 직접 조정할 수 있는 기능이 있을 수 있습니다.
하지만 어떤 clock이 MGT의 clock output port에 노출되어 있을까요? 자연스러운 답은 XCLK입니다. 이 clock이 logic fabric의 clock에 대한 요구 사항에 가장 가까운 후보이기 때문입니다. 그러나 logic fabric의 clock을 생성하는 데는 몇 가지 다른 가능성이 있습니다. 예를 들어, MGT의 clock output을 일반 logic fabric PLL 에 공급하여 다른 frequency가 있는 clock을 생성할 수 있습니다. 이 PLL은 clock buffer와 함께 사용되므로 clock signal이 해당 목적에 적합합니다. 이런 방식으로 PLL을 사용하면 새로운 가능성이 열립니다. 예를 들어 MGT가 clock output port에서 자체 reference clock을 통과할 수 있습니다. 이 clock 의 frequency는 MGT와의 인터페이스에 clock을 사용하기에 적합하지 않을 수 있지만, PLL은 이 clock을 필요한 비율로 곱할 수 있습니다.
또한 logic fabric의 clock 의 frequency는 XCLK의 frequency와 다를 수 있습니다. 이는 PCS내부에서 asynchronous gearbox가 활성화될 때 필요할 수 있습니다. 이 시나리오에서 frequency 차이는 PMA 와 logic fabric와의 인터페이스에서 병렬 단어의 다른 너비를 보상하는 데 필요합니다.
이 주제와 관련된 규칙은 복잡하고 FPGA 마다 다릅니다. MGT설명서의 상당 부분은 종종 다양한 가능성을 자세히 설명하는 데 전념합니다. 안타깝게도 clocking 에서 올바른 결정을 내리려면 특정 FPGA에 적용되는 규칙을 배우는 데 시간을 할애해야 합니다.
데이터 수신을 위한 logic fabric clock 선택
데이터 수신을 위한 logic fabric의 clock을 생성하는 방법을 선택할 때 기본적인 결정이 필요합니다. 이 clock이 CDR의 clock 에서 파생되었는지 아니면 고정된 reference clock에서 파생되었는지. 다시 말해, logic fabric의 clock이 도착하는 데이터 스트림의 정확한 데이터 속도에 맞춰졌는지 여부입니다.
대부분의 애플리케이션에서 MGT는 양방향 데이터 통신에 사용됩니다. 도착하는 데이터와 전송되는 데이터 간에는 종종 긴밀한 관계가 있습니다. 예를 들어, 전송되는 데이터 스트림에는 도착하는 데이터 스트림에 대한 응답으로 전송되는 확인 및 재전송 요청이 포함될 수 있습니다. 이러한 종류의 애플리케이션에서는 모든 logic이 동일한 clock 와 동기화되는 것이 편리합니다(즉, 모든 logic이 동일한 clock domain 에 있음). 특히, PIPE 인터페이스는 MGT가 있는 모든 인터페이스가 단일 clock (표준 문서에서는 PCLK 라고 함)와 동기화되어야 합니다. 앞서 PIPE이 MGTs 와 여러 protocols간의 표준 인터페이스라는 점을 상기해 보세요. PCIe, SuperSpeed USB 및 SATA.
하지만 이러한 편의성에는 비용이 따릅니다. logic fabric의 clock 중 frequency는 PMA의 병렬 단어(즉, XCLK의 frequency)와 함께 사용되는 frequency 와 약간 다를 수 있습니다. 이 차이로 인해 logic fabric이 병렬 단어를 PMA에 도착하는 것보다 느리거나 빠르게 수신하기 때문에 PCS내부에 데이터가 잉여되거나 부족해집니다. 이에 대한 해결책은 종종 PCS페이지 에서 설명한 대로 Rx buffer 와 skip symbols를 사용하는 것입니다.
또는 logic fabric의 clock은 PMA의 clock에서 파생될 수 있습니다. 이 방법을 사용하면 logic fabric은 데이터가 도착하는 것과 같은 속도로 데이터를 소비합니다. 이는 MGT가 데이터를 수신하는 데만 사용될 때 자연스러운 솔루션입니다. 또한 애플리케이션 logic이 clock domain crossing을 처리할 때 양방향 링크에 대한 가능한 선택입니다. Xillyp2p는 이 접근 방식을 취한 protocol 의 예입니다.
AMD FPGA: logic fabric에서 두 개의 clocks
AMD FPGAs (이전 명칭 Xilinx)의MGTs 에는 logic fabric에서 2개의 clock input ports가 있습니다. 즉, 각 방향에 대해 2개의 ports가 있습니다. 송신에는 TXUSRCLK 와 TXUSRCLK2가 있고, 수신에는 RXUSRCLK 와 RXUSRCLK2가 있습니다.
logic fabric 와의 거의 모든 인터페이스는 TXUSRCLK2 또는 RXUSRCLK2 (방향에 따라 다름)와 동기화됩니다. 다른 두 개의 inputs, TXUSRCLK 및 RXUSRCLK는 PCS의 일부 부분에서 내부적으로만 사용됩니다.
TXUSRCLK는 종종 TXUSRCLK2와 동일한 clock signal 입니다. 그러나 AMD의 FPGAs 에 있는 MGTs는 logic fabric 와의 인터페이스에서 사용되는 병렬 워드가 PCS내부보다 두 배 더 넓을 수 있는 기능이 있습니다. 이 기능을 사용하면 TXUSRCLK의 frequency는 TXUSRCLK2의 frequency 의 두 배입니다. 이것이 logic fabric PLL을 사용하는 또 다른 이유입니다.
동일한 원리가 RXUSRCLK 와 RXUSRCLK2에도 적용됩니다.
요약
이 페이지에서는 MGT의 clocks와 관련된 몇 가지 주제를 간략하게 강조했습니다. 그럼에도 불구하고 MGT의 clocking resources활용에 대한 현명한 결정을 내리기 위해서는 MGT의 특정 기능과 제한 사항에 대해 알아야 합니다. 이 페이지의 설명이 MGT의 clocks가 어떻게 작동하고 서로 상호 작용하는지 이해하는 데 도움이 되기를 바랍니다.
이것으로 MGTs에 대한 시리즈 의 마지막 페이지를 마치겠습니다.