범위
이 페이지는 FIFOs에 관한 5페이지로 구성된 시리즈 중 두 번째 페이지입니다. 이전 페이지 에서 FIFO 의 기본 사항을 제시한 후, 이제 일반적인 변형과 추가 기능에 대해 논의할 차례입니다. FIFO는 아래 설명된 옵션의 조합으로 구성되는 경우가 많습니다.
Single clock FIFOs
"baseline FIFO"에는 관련 없는 clocks에 대해 두 개의 inputs가 있지만 양쪽의 신호가 동일한 clock와 동기화되는 경우가 종종 있습니다. 이 동일한 clock을 @wr_clk 및 @rd_clk에 연결하는 것은 완벽합니다. 그러나 두 clock inputs에서 동일한 clock이 므로 clock domain crossing이 필요하지 않으므로 FIFO 에는 불필요한 logic이 포함됩니다. clock domains 에 대한 자세한 내용은 여기 에서 확인할 수 있습니다.
따라서 모든 FPGA 공급업체는 FIFO에 대해 두 가지 범주를 제공합니다. Dual-clock FIFO 및 single-clock FIFO. 다른 이름이 자주 사용됩니다. Independent Clock FIFO 대 Common Clock FIFO 또는 Asynchronous FIFO 대 Synchronous FIFO. 이전 페이지 에 소개된 "baseline FIFO"는 dual-clock FIFO입니다.
모든 logic은 동일한 clock와 동기화되므로Single-clock FIFOs 에는 synchronization logic이 없습니다. 따라서 reset input은 다른 ports와 동일한 clock 와 동기화되어야 합니다.
FPGA logic을 낭비하지 않는 것을 제외하고 single clock FIFOs를 사용하는 또 다른 좋은 이유는 명확성을 위해서입니다. 두 개의 clocks를 포함할 의도가 없음을 크고 명확하게 표현하는 방법입니다.
간단히 말해서: FIFO가 두 clock domains사이에 연결되지 않으면 single-clock FIFO로 이동하십시오.
FWFT FIFOs
앞 페이지 에서 강조했듯이 "baseline FIFO"에서 데이터를 읽는 절차는 @rd_en을 high로 변경하고 다음 clock cycle에서 FIFO의 @dout output 에서 값을 얻는 것입니다. 다소 직관적이지 않습니다. 데이터가 이미 FIFO에 있는 경우 이를 요청해야 하는 이유는 무엇입니까? 왜 FIFO는 그냥 @dout port에 올려놓고 써도 괜찮다고 말해주면 안되나요?
따라서 정확히 이를 수행하는 일반적인 변형이 있으며 First Word Fall Through FIFO (FWFT, 때로는 read-ahead, show-ahead 또는 look-ahead라고도 함)라고 합니다. FWFT FIFO 의 반대는 종종 "Standard FIFO"(누가 나에게 표준을 보여줄 수 있습니까?)라고 합니다.
아이디어는 간단합니다. FWFT FIFO가 비어 있는 것을 멈추면(데이터가 기록되었기 때문에) @dout의 첫 번째 단어를 표시합니다. 그런 다음 application logic은 @rd_en을 높게 유지하여 단어를 읽습니다. 따라서 차이점은 첫 번째 단어에 관한 것입니다.
그러나 ports 중 두 가지의 의미가 변경되었음을 인식하면 FWFT FIFO를 이해하는 것이 더 쉽습니다. FWFT FIFO 의 @rd_en은 실제로 " @dout에서 데이터를 소비했습니다. 다음 데이터를 가져와도 좋습니다."를 의미하고 @empty는 실제로 "@dout가 유효하지 않음"을 의미합니다.
변경되지 않은 것은 @empty가 높으면 @rd_en이 높으면 안 된다는 것입니다. 잘못된 데이터를 소비했다고 말할 수 없습니다. 따라서 규칙은 다른 이유로 동일하게 유지됩니다.
다음 waveform은 FWFT FIFO 에서 읽는 것이 어떤 모습일 수 있는지 보여줍니다.
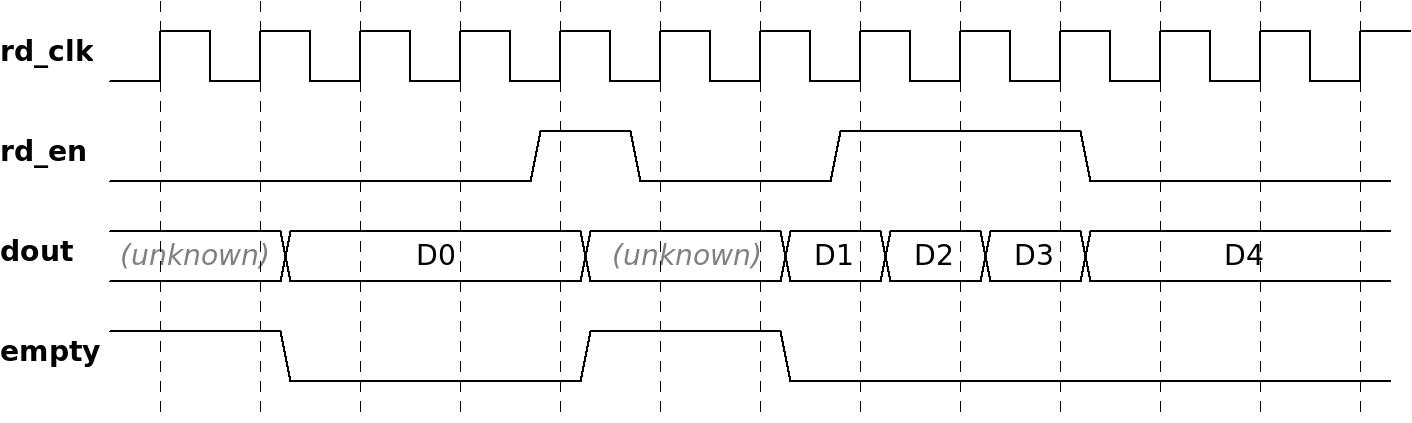
@dout 의 첫 번째 유효한 값은 @rd_en이 로우인 동안 나타나고, @empty는 유효한 값이 나타나는 것과 동시에 로우로 변경됩니다. 방금 언급했듯이 @empty는 FWFT FIFO에서 "@dout가 유효하지 않음"을 의미하며 waveform은 이를 반영합니다.
또한 @rd_en 의 첫 번째 펄스는 FIFO에서 새 값을 읽지 않고 오히려 @empty가 다시 high로 변경되도록 했습니다. 이에 따라 @dout 의 값도 동시에 알 수 없게 되었다. 실제로 @dout는 일반적으로 @empty가 high로 변경될 때 변경되지 않지만 그것에 의존할 수는 없습니다.
그 후 FIFO는 다시 한번 @dout 에 값을 넣고 @empty를 low로 변경합니다. application logic은 세 단어를 읽은 다음 @rd_en을 low로 변경합니다. 전체적으로 application logic은 FIFO에서 4~5개의 단어를 소비했습니다.
waveform은 application logic이 D4 의 값도 사용했는지 여부를 알려주지 않습니다. 다섯 번째 단어를 무시했을 수 있습니다. 즉, 네 단어만 소비했다는 의미입니다. 또는 다섯 번째 단어의 값을 사용했을 수 있습니다. waveform 에서 분명한 것은 application logic이 4개의 clock cycles이후에 @rd_en을 낮게 유지했기 때문에 FIFO가 @dout를 계속 업데이트하는 것을 허용하지 않았다는 것입니다.
주의해야 할 또 다른 사항은 FIFO의 메모리 내부에 더 많은 데이터가 있는지 알 수 없다는 것입니다. 이 waveform 의 끝에서 @empty가 낮다는 사실은 단지 @dout가 유효하다는 것을 의미합니다.
이제 이전 페이지 의 Verilog 예제를 수정해 보겠습니다. 다시 한 번, 이 코드는 FIFO에서 나오는 모든 것의 누적 합계를 계산합니다.
assign rd_en = !empty; // If @dout's value is valid, it's consumed.
always @(posedge rd_clk)
if (!empty) // FIFO is FWFT, so !empty means @dout contains valid data
sum <= sum + dout; // Don't try this at home: @sum is never reset.
이전 예제와 달리 FWFT FIFO를 사용하므로 이전 clock cycle에서 @rd_en 값을 가진 register가 필요하지 않습니다. 대신 @empty가 낮을 때 @dout를 사용할 수 있습니다. 이 간단한 규칙은 @empty가 낮을 때 @rd_en이 높기 때문에 작동하므로 FIFO 의 각 단어는 정확히 하나의 clock cycle에 대해 @dout 에서 유효합니다.
약간 관련이 없는 요점으로 FWFT 주제를 마무리하고 싶습니다. "표준" FIFO와 FWFT FIFO 의 차이점은 logic의 두 modules 간의 데이터 흐름과 관련된 근본적인 문제를 반영합니다. 수신측에서 데이터를 요청해야 합니까? 아니면 보내는 쪽에서 가능한 한 빨리 데이터를 제공하고 받는 쪽에서 계속해도 되는지 확인만 합니까? 한 module이 다른 module 로 데이터를 전달할 때 항상 자신에게 이 질문을 하십시오. 특히 이 modules가 이 문제에 동의하는지 스스로에게 물어보십시오.
Asymmetric FIFOs
@din 및 @dout에 대해 다른 너비로 FIFO를 정의하는 것이 일반적으로 허용됩니다. 이는 예를 들어 데이터가 32비트 워드로 FPGA 에 도착하지만 application logic이 이를 바이트, 즉 워드당 8비트로 처리하는 경우에 유용합니다. 이 경우 쓰기 쪽의 너비를 32비트로, 읽기 쪽의 너비를 8비트로 설정합니다. 단일 write cycle와 함께 삽입된 단어를 소비하는 데 4개의 read cycles가 필요하다는 점을 제외하면 양측은 평소와 같이 동작합니다.
읽는 쪽이 쓰는 쪽보다 넓을 때 예상대로 작동합니다. FIFO 에 기록된 데이터는 기록된 데이터가 읽기 쪽 크기의 워드를 채울 때까지 읽기 쪽에서 사용할 수 없습니다.
단어가 패킹되는 순서는 모든 FIFOs가 Little Endian을 사용하는 것 같습니다. 예를 들어, FIFO는 다음과 같이 32비트 워드를 8비트 워드로 묶습니다. FIFO 에서 읽은 첫 번째 워드의 비트 범위는 [7:0]이 고 다음으로 [15:8], [23:16] 및 [31:24]입니다.
그러나 이 기능을 사용하려면 항상 설명서를 확인하십시오.
@empty 및 @full에서 combinatorial logic 와의 종속성
@empty 와 @full ports는 공통적으로 다음과 같은 단점을 가지고 있습니다. application logic은 동일한 clock cycle에서 이에 응답해야 합니다. 다시 말해, @rd_en은 이 두 signals가 동일한 clock cycle 에서 높지 않도록 하기 위해 @empty 에 의존하는 조합 함수여야 합니다(이미 언급했듯이 이는 금지됨). 마찬가지로 @wr_en은 @full에 의존하는 combinatorial function 여야 합니다.
combinatorial functions 의 사용은 timing constraints를 달성하는 데 장애가 될 수 있습니다. 이것은 clock의 주파수가 높고( FPGA의 사양에 비해) logic function이 복잡할 때 문제가 될 수 있습니다. 문제의 주요 원인은 @rd_en 와 @wr_en이 데이터를 생성하거나 소비하는 logic 에서 자주 사용되기 때문입니다. 특히, 많은 logic 에 대해 clock enable을 계산하는 logic function은 이러한 신호에 의존할 수 있습니다. 예를 들어, FIFO에서 오는 데이터를 처리하는 긴 pipeline이 있는 경우 pipeline 의 모든 logic은 FIFO 의 데이터 흐름이 일시적으로 중지될 때 정지되어야 합니다.
글쎄요, 완전히 정확하려면 combinatorial function을 피할 수 있는 방법이 있습니다. 예를 들어, @wr_en이 register로 선언되고 @want_to_write가 주어진 시간에 써야 하는 application logic의 필요성을 나타내는 신호라고 가정합니다. 다음과 같이 할 수 있습니다.
always @(posedge wr_clk)
wr_en <= want_to_write && !wr_en && !full;
이렇게 하면 @wr_en이 하이가 된 후에 @full이 clock cycle 에서만 하이로 변경할 수 있기 때문에 @wr_en 와 @full이 동일한 clock cycle에서 결코 하이가 되지 않습니다. 표현식의 !wr_en 부분은 @wr_en이 두 개의 연속적인 clocks cycles동안 절대로 하이가 되지 않도록 합니다. 따라서 @full이 high로 변경되면 첫 번째 clock cycle의 !wr_en 때문에 @wr_en이 Low가 됩니다. @wr_en은 @full 자체로 인해 낮은 상태를 유지합니다.
그러나 이 솔루션을 사용하면 @wr_en이 절반의 시간 동안 낮아야 합니다. 결과적으로 FIFO의 데이터 전송률 중 50% 만 사용됩니다. 이것은 일반적으로 허용되지 않습니다.
@rd_en에서도 동일한 솔루션이 가능하며 이 솔루션은 데이터 전송률의 절반을 사용하는 것과 동일한 문제가 있습니다.
이 토론은 다음 섹션으로 이어지도록 의도되었습니다. "almost" ports.
Almost full, almost empty 및 유사 ports
FIFO에 두 개의 옵션 포트를 추가할 수 있습니다. @almost_full port 및/또는 @almost_empty port.
@almost_empty는 @rd_clk와 동기식이며 @empty와 유사하지만 약간의 차이가 있습니다. @almost_empty는 FIFO가 비어 있을 때 높지만 FIFO에서 읽을 정확히 한 단어가 있을 때도 높습니다.
마찬가지로 @almost_full은 @wr_clk와 동기식이며 FIFO가 가득 찼을 때 높지만 FIFO에 정확히 한 단어를 써도 괜찮습니다.
이 두 output ports 의 이름은 FPGA 공급업체와 공급하는 소프트웨어에 따라 다르지만 항상 동일한 기능을 가진 ports를 추가할 가능성이 있습니다. 때때로 FIFO 의 특정 변형이 이러한 ports를 지원하지 않을 수 있습니다.
이러한 ports가 어떻게 도움이 됩니까? 글쎄, 이것은 완벽하게 작동하기 때문에 :
always @(posedge wr_clk)
wr_en <= want_to_write && !almost_full;
combinatorial logic이 없으며 write cycles의 절반을 건너뛸 필요가 없습니다. @almost_full이 하이일 때 @wr_en은 동일한 clock cycle에서 로우로 변경되지 않고 다음 X에서만 변경될 수 있습니다. 결과적으로 @almost_full이 high로 변경된 후 하나의 쓰기 작업이 있을 수 있습니다. 그러나 한 단어에 대한 장소가 있으므로 괜찮습니다.
FIFO가 채워지는 동안 @want_to_write가 계속 하이로 유지되면 마지막 쓰기 작업이 FIFO를 완전히 채웁니다. 그렇지 않으면 FIFO가 거의 채워질 수 있습니다. @want_to_write로 인해 @wr_en이 낮고 그로 인해 FIFO가 완전히 채워지지 않으면 두 번째 기회가 없습니다. @almost_full은 다른 쪽이 FIFO에서 데이터를 읽을 때만 로우로 변경되므로 FIFO에는 두 개 이상의 워드를 위한 공간이 있습니다.
이것은 거의 중요하지 않지만 토론을 위해 마지막 단어가 사용되도록 합니다.
always @(posedge wr_clk)
wr_en <= want_to_write && (!almost_full || (!full && !wr_en));
@wr_en 에 대한 이 표현식은 정확히 한 단어를 쓰는 것이 좋은 경우를 제외하고 대부분의 경우 @almost_full 에 의존합니다. 그제서야 @wr_en은 @full 와 @wr_en에 의존하게 되는데, 이는 앞서 !wr_en을 사용한 표현과 유사합니다.
그러나 나는 @wr_en 의 마지막 표현이 유용한지 심각하게 의심합니다.
@almost_empty 의 이야기는 비슷하므로 이것은 괜찮습니다(그러나 이것을 코드에 복사하지 마십시오).
always @(posedge rd_clk)
rd_en <= want_to_read && !almost_empty;
@almost_full와 마찬가지로 마지막 단어에 문제가 있습니다. @want_to_read때문에 @rd_en이 낮으면 FIFO가 더 많은 데이터로 채워질 때까지 기회를 잃습니다. @almost_full의 경우와 달리 이것은 일부 시나리오에서 확실히 문제가 될 수 있습니다. @almost_empty가 높지만 FIFO가 비어 있지 않으면 FIFO 에 읽기 위해 의도된 데이터가 있지만 이 데이터는 FIFO에 남아 있음을 의미합니다.
따라서 이것이 안전한 방법입니다.
always @(posedge rd_clk)
rd_en <= want_to_read && (!almost_empty || (!empty && !rd_en));
Fill counters
Application logic은 종종 청크로 작업을 수행합니다. 예를 들어 FIFO 에서 일정한 길이의 데이터 패킷을 읽고 이러한 패킷을 일부 물리적 미디어를 통해 전송하는 logic이 있습니다. 데이터가 FIFO에 저장되기 때문에 application logic은 읽기를 시작하기 전에 패킷을 채울 만큼 데이터가 충분하다는 것을 알아야 합니다.
마찬가지로 application logic은 FIFO에 저장하기 위해 고정된 양의 데이터를 생성하는 경우가 많습니다(예: 외부 메모리에서 burst 데이터 읽기). FIFO 에 burst를 완료하기에 충분한 공간이 없으면 작업이 시작되지 않습니다.
이러한 목적을 위해 FIFOs는 일반적으로 fill counters, programmable empty port 및 programmable full port를 지원합니다. fill counters ( data counters라고도 함)는 FPGA 공급업체에 따라 다양한 형태와 모양으로 제공되므로 FIFO의 설명서를 주의 깊게 읽으십시오. 주의해야 할 세 가지 주요 문제가 있습니다.
- counter는 어떤 clock 와 동기화됩니까? 거의 말할 필요도 없이 counter를 사용하는 logic 와 동일한 clock 여야 합니다.
- counter는 우리에게 무엇을 말합니까? "Read counters"는 일반적으로 FIFO에 저장된 단어 수를 나타내지만 "write counters"는 어떻습니까? 그것도 저장된 단어의 수입니까, 아니면 FIFO가 가득 찰 때까지 쓸 수 있는 단어의 수입니까?
- counter는 무엇을 보장합니까? Fill counters는 일반적으로 의도한 목적과 관련하여 비관적입니다. 예를 들어 "read counters"는 FIFO의 실제 단어 수보다 일시적으로 더 적은 수를 부여하는 것이 일반적입니다. 이것은 counters가 쓰기 작업에 대한 응답으로 늦게 값을 증가시키지만 읽기 작업에 대한 응답으로 일찍 값을 감소시키기 때문에 워드가 FIFO에 기록되는 동안 발생합니다. 이것은 @rd_en을 제어하는 logic 와 함께 사용하는 데 적합하지만 이러한 종류의 counter가 @wr_en을 제어하는 logic 에서 사용되는 경우 overflow가 발생할 수 있습니다. 이를 위해 "write counters"가 있습니다. 그럼에도 불구하고 설명서의 세부 사항을 읽으십시오.
또한 @almost_empty 및 @almost_full의 확장 버전인 programmable empty 및 programmable full이 있습니다. 아이디어는 fill counters 의 사용이 거의 확실하기 때문에
assign dont_start_reading = (rd_data_count < 64);
그 신호를 직접 제공하고 prog_empty라고 부르지 않겠습니까? 다시 한 번, FIFO의 문서를 주의 깊게 읽으십시오.
다시 한 번, FIFO의 마지막 단어를 읽는 것이 중요할 때 logic이 실제로 그렇게 할 것인지 스스로에게 물어보십시오. 이 질문은 @almost_empty에 대한 위의 논의와 유사합니다.
말할 필요도 없이 FIFO를 구성할 때 이러한 추가 ports를 요청해야 합니다.
AXI interface
이 주제는 직접적인 관련이 없지만 혼동을 피하기 위해 언급할 가치가 있습니다. 이 용어는 종종 FIFOs와 관련하여 나타납니다.
AXI는 ARM에 의해 도입된 AMBA 표준에 정의된 인터페이스 집합입니다. 예상할 수 있듯이 AXI 인터페이스가 있는 FIFOs는 일반적으로 CPU의 주변 장치로 작동하도록 고안되었습니다.
"baseline FIFO"의 인터페이스는 종종 AXI 인터페이스와 반대되는 "native" 인터페이스라고 합니다.
AXI 인터페이스에는 두 가지 주요 유형이 있습니다. "일반" AXI (일반적으로 AXI3, AXI4 또는 AXI Lite)는 address 및 data를 갖춘 bus 입니다. 두 번째 유형인 AXI-S (streamed AXI)는 데이터(아마도 패킷으로 나뉜)의 streams를 위한 것입니다.
FIFO가 AXI3 / AXI4 또는 AXI Lite로 구성되면 추가 logic이 여기에 추가되어 이 인터페이스를 통해 CPU 에 주소가 있는 주변 장치로 연결할 수 있습니다. 이것은 완전히 다른 주제이기 때문에 더 이상 자세히 설명하지 않겠습니다.
그러나 streaming 인터페이스는 FIFO의 동작과 다소 유사하기 때문에 AXI-S 인터페이스의 handshake signals를 "native" 인터페이스로 변환할 수 있습니다. AXI-S는 종종 경향이 필요한 다른 신호를 포함합니다.
따라서 FIFO 에 @axi_w_valid, @axi_w_ready 및 @axi_w_data로 쓰기 위한 AXI-S 신호가 주어지면 "표준" FIFO 의 ports 에 연결할 수 있습니다.
assign axi_w_ready = !full;
assign wr_en = axi_w_valid && axi_w_ready;
assign din = axi_w_data;
마찬가지로 FIFO, @axi_r_valid, @axi_r_ready 및 @axi_r_data에서 읽기 위한 AXI-S 신호는 다음을 사용하여 FWFT FIFO 의 ports 에 연결할 수 있습니다.
assign axi_r_valid = !empty; // Non-empty means valid with FWFT FIFOs
assign rd_en = axi_r_valid && axi_r_ready;
assign axi_r_data = dout;
다시 한 번, 이것이 작동하려면 FIFO가 FWFT 변형이어야 합니다.
이것으로 FIFOs에 대한 이 시리즈 의 두 번째 페이지를 마칩니다. 다음 페이지 는 single-clock FIFO가 Verilog에서 어떻게 구현되는지 보여줍니다.