このページは clock domainsに関する 3 つのシリーズの 2 番目です。
範囲
前のページですでに述べたように、 path が related clocksの clock domains にまたがる場合、 logicでは特別な処理は必要ありません。それにもかかわらず、 FPGA ツールがこの pathで timing constraints を強制することを確認して、宛先 (setup および hold) で synchronous element のタイミング要件を保証する必要があります。したがって、このケースは、 path にタイミングが設定されているという意味で、 clock domain crossing がまったくないかのように処理されます。
ただし、 clocks が unrelated clocksの場合、 resynchronization logic が必要です。 この問題を解決する専用の Verilog (または他の言語) のコードが必要です。このページでは、これを行う方法の基本について説明します。
可能であれば FIFO を使用してください
逃げる可能性がある人のために、この頭痛を完全に回避する方法から始めるのが公正だと思いました.それは次のとおりです。
FPGA ツールによって生成されるDual-clock FIFOsは、間違いなく clock domainsを通過する最も安全な方法です。これは最も一般的な解決策であり、この方法が非常に広く使用されているという事実自体が、この方法を信頼する理由です。
特に、 FPGAsを初めて使用する場合は、 design を少し変更する必要があるとしても、 FIFOを好む十分な理由があります。 FIFO を使用すると、目的に合わせて調整された logic よりもわずかに多くのリソースを消費する可能性があります。ただし、 FIFOの奥行きが浅い場合、 block RAM は通常必要ありません。したがって、その違いは、混乱するリスクに見合うだけの価値があるとは限りません。
多くの場合、 FIFO は、特に 1 つの機能ユニットから別の機能ユニットに data stream がある場合に、 clock domainsにまたがる自然なソリューションです。しかし、それほど自然ではない場合でも、 logic を再編成して適合させることができる場合がよくあります。たとえば、ある clock domain の logic が別の clock domain の logic に何らかのイベントについて通知する必要がある場合、これはメッセージ ワードをエンコードし、それを浅い FIFOに書き込むことによって実行できます。この種のソリューションは、バグが発生しにくいだけでなく、 designがより整理されて読みやすくなる可能性もあります。
FIFOs の接続方法と使用方法については、この一連のページで詳しく説明されています。
単一の bit用のResynchronization logic
FIFO で問題が解決しない場合は、安全な clock domain crossingのために袖をまくり上げて resynchronization logic を実装するときです。このページの残りの部分は、単一の bitの幅を持つ信号で clock domains を通過することに限定されています。これはあらゆる resynchronization logicの基礎であり、この一見単純なケースについては多くのことが言えます。
このシリーズの次のページでは、以下に示す metastability guard 技術に基づいて、より広い信号で clock domains を通過する方法について説明します。
Metastability
解決策に進む前に、 flip-flop の timing requirements が違反された場合に何が起こるかを理解することが重要です。言い換えると、 clock edgeの前の tsu で始まり、その後の thold で終わる期間に、 data input の信号が安定していない場合です。関連する clock edge は、もちろん flip-flopの clock inputのものです。この clock edge が data inputをサンプリングする原因となります。
明らかに、この期間中にデータが変更された場合、この clock edge の後の flip-flop の output は予測できません。しかし、それはそれよりもさらに悪いです: flip-flop が flip-flopの outputで合法的な '0' または '1' を示すのに、通常よりもかなり長い時間がかかる場合があります。 flip-flop は、 output をこれら 2 つの可能な値 (つまり、 '0' または '1') のいずれかで安定させるように設計されていますが、 timing requirements に違反すると、 flip-flop がしばらく不安定な状態に留まる可能性があります。または、公式用語を使用すると、 flip-flop は metastableです。
flip-flop が到達できる不安定な状況を描写するためによく使用される、丘の先端にボールが立っているという決まり文句のイメージを省略しません。
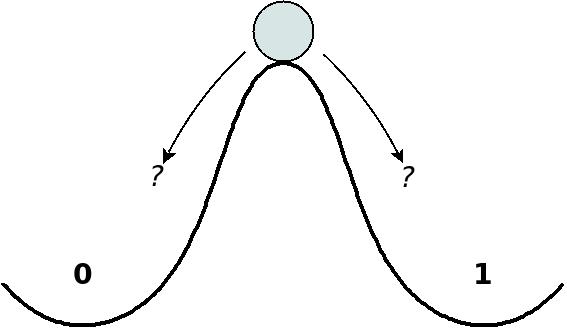
Metastability は、 flip-flop が最終的に何に着地するかの不確実性よりも、はるかに大きな問題です。これは特に、 flip-flopの output が複数の宛先に接続されている場合に当てはまります。 '0' または '1'に着陸するのに時間がかかるため、送信先の flip-flops では信号が安定するのが遅すぎる可能性があります。その結果、送信先の一部の flip-flops はウォブリング信号を '0' として受信し、他の flip-flops は '1'として受信する場合があります。この不一致により、 logic が不正な状態になる可能性があり、この状況から logic が black magic スタイルで動作する可能性があります。したがって、 metastability の危険にさらされている flip-flop は、複数の logic elementに接続しないでください。
metastabilityに取り組むには、 flip-flop がいずれかの安定状態に陥るまでにかかる時間を知っておくとよいでしょう。残念ながら、それに対する明確な答えはありません。これは、ボールが丘の頂上にどれくらい留まるかを尋ねるのとまったく同じです。 それは多くの要因に依存し、ランダムな振動が最終的にこの方法または他の方法で落下する可能性があります. flip-flopの metastabilityと同じ: この状態は、電子回路のランダム ノイズなどによって解除されます。
理論的には、 flip-flop は metastability の状態を永遠に維持できますが、実際には、しばらくすると安定した状態のいずれかに陥ります。この状態でいる時間が random variableです。そして、この random variableの動作を推定するために、多くの実験とシミュレーションが行われました。ただし、動作は siliconの製造技術、温度、 crosstalk のノイズレベルなどに依存するため、これらの試みはどれも実際には関係ありません。
したがって、 metastabilityの状態で flip-flop が決して超えない最大時間を指定できれば便利ですが、そのような制限はありません。 flip-flops は製造工程が新しくなったため、 metastability の状態がすぐに消えてしまう傾向があるため、おおよその数値を取得することさえできません。
代わりに、これは慣れるべきアイデアです: clock domains と unrelated clocksを比較すると、一部の flip-flop が design が許容できるよりも長く metastability の状態のままになる可能性が常にあり、その結果として何か問題が発生します。 designers としてできることは、このリスクを減らすことだけです。せいぜい、一緒に暮らすことができる MTBF (Mean Time Between Failure) を実現できます。
幸いなことに、それを正確に達成するための十分に確立された手法があるので、次のトピックに進みます。
metastability guard
長い話を短くするために、前のページの最初のコード例をもう一度見てみましょう。 @clk1 と @clk2 が unrelated clocksである場合、 @foo から安定した @bar を取得するための共通の resynchronization logic は、
reg foo, bar, bar_metaguard;
always @(posedge clk1)
foo <= !foo;
always @(posedge clk2)
begin
bar_metaguard <= foo;
bar <= bar_metaguard;
end
名前が示すように、 @bar_metaguard は metastability guardです。 @bar_metaguard を実装する flip-flop のタイミング要件は、 @fooのサンプリング中に時々違反されます。そのため、 @bar_metaguard には metastabilityの短い瞬間がある場合があります。この flip-flop はこの状態からすぐに回復すると予想されるため、 @barの setup timing requirementを満たすのに十分早く安定します。したがって、 @bar は @clk2の clock domain内で確実に使用できます。
この説明は不正確に聞こえるかもしれませんが、実際にそうです。 metastabilityに対するフェイルセーフ ソリューションがないため、上記で metastability について書いたことと実際には矛盾しています。これについては、後で説明します。しかし、今のところ、上記のように metastability guard を追加するという一般的な方法に固執し、もう心配する必要はありません。実を言うと、これで問題を抱えている人については聞いたことがありません。
さらに安全性を高めたい場合は、 registersを追加してください。したがって、ダブル metastability guard は次のようになります。
reg foo, bar, bar_metaguard_a, bar_metaguard_b;
always @(posedge clk1)
foo <= !foo;
always @(posedge clk2)
begin
bar_metaguard_a <= foo;
bar_metaguard_b <= bar_metaguard_a;
bar <= bar_metaguard_b;
end
@bar_metaguard_a は最初の metastability guardです。運が悪ければ、 metastability の状態に長く留まり、 @bar_metaguard_bの timing requirements が破られます。その結果、 @bar_metaguard_b は次の clock cycleで metastability の周期を持ちます。しかし、今回は metastability の周期が短いので、次のことが期待できます。 雷が一箇所に二度落ちることはない、と彼らは言います。しかしもちろん、 @bar_metaguard_b は、 @barの timingに違反するのに十分な時間、 metastability 状態にとどまることができます。しかし、その確率は?目標は妥当な MTBFを入手することであることを忘れないでください。
要約する: 単一の bitで clock domain を通過する方法についてのクックブック ソリューションを探しているなら、これがそれです。 1 台の metastability guard または 2 台の metastability guards でうまく機能します。決して失敗しないソリューションを探している場合、残念ながらこれは不可能です。しかし、事故の可能性を可能な限り減らしたい場合は、読み進めてください。
metastabilityのTiming analysis
それでは、単一の metastability guardを使用した上記の例に戻り、 @bar_metaguard が metastability から十分に迅速に回復すると確信していた理由を尋ねてみましょう。答えは、すでに述べたように、確かな理由はないということです。
それでも、 timing analysisを少し作ってみましょう。 @bar_metaguard と @bar はどちらも同じ clockと同期しています。これらの registers に特別な timing constraints が割り当てられていないと仮定すると、それらの間の path は @clk2の timing constraint (clock period) によって制限されます。言い換えれば、ツールは、 metastabilityがない場合、 @bar の input signal が正当な timingでサンプリングされることを保証します。
しかし、 @bar_metaguard の重要な点は、 metastability が時々許可されることです。したがって、 timing analysis では不十分です。 実際には、 flip-flop が metastability 状態で過ごす時間は、 clock-to-output 時間に追加されます。言い換えると、 metastability は、 flip-flop の output が通常の delayよりも遅く安定することを意味します。したがって、 @bar_metaguard と @bar の間の path の slack がほぼゼロである場合 (つまり、 propagation delay は timingを達成するのに十分ですが、余裕はありません)、 metastability によって pathの合計 delay が許容限度を超える可能性があります。このようなイベントにより、 @barの inputで timing violation が発生します。もちろん、これは温度、電圧、製造プロセスの最悪のケースに当てはまりますが、それでも: ツールが通常の timing constraint を metastability guardの output に適用するということは、必要な timing requirementsが保証されないことを意味します。
幸いなことに、これは簡単に修正できます。または改善する、と私は言うべきです。この方法は、信頼性が必要な metastability guards から registers までのすべての paths に、よりタイトな timing constraint を追加することです。言い換えれば、これらの pathsでは propagation delay を少なくするという考えです。 propagation delayに許可される時間を短縮することにより、この時間は metastabilityからの回復のために与えられます。
たとえば、すべての metastability guard registers に *_metaguard 接尾辞が付いている場合、単一の timing constraint を記述して、それらのすべての paths が安定するために余分な時間を取得することを要求できます。 Vivadoの場合、そのような constraint は次のようになります。
set_max_delay -from [ get_cells -hier -filter {name=~*_metaguard*} ] 0.75
(set_max_delay はタイミング例外に関するページで説明されています )
この timing constraint は、 metastability guard で始まるすべての path が、その宛先に到達する 0.75 ns を持っていることを意味します (これらの paths は、 registersの名前のサフィックスによって選択されます)。これは、これを試した特定の FPGA で timing constraint を失敗させることなく取得できた最小遅延です (したがって、他の FPGAsでは異なる場合があります)。この数値に到達する方法は、ツールがこの constraintを達成できなくなるまで、より低い数値を選択することです。この失敗時に、必要に応じてこの数を増やして、非常に小さな slack (例: 0.2 ns) を実現します。これにより、ツールはこれらの pathsで最善を尽くすことになります。
この set_max_delay command は、 0.75ns (1333 MHz) の clock period を要求することと同じです。したがって、たとえば、実際の clock period が 250 MHz (4 ns) である場合、この timing constraint を達成すると、少なくとも 4 – 0.75 = 3.25 nsの余剰が得られます。したがって、 metastability guards が 3.25 nsまで metastability 状態にある場合、この set_max_delay constraintのおかげで、 timing violation は発生しません。
もちろん、これはまったく保証がないよりはましですが、 3.25 ns で十分でしょうか?多いですか? clock domainsの実質的なフェイルセーフ移行を保証するだけで十分ですか?
すでに述べたように、これに対する答えはいくつかの要因によって異なります。公開された実験から判断すると、私の個人的な印象では、今日実際に使用されている FPGA で、 flip-flop が 1 nsと同じくらい長く metastability 状態のままになることはほとんどありません。しかし、この件に関して確実なことを言うのは難しいです。
しかし、この timing constraintを追加することで、ツールに最善を尽くすように促すことで、 FPGA design を他の誰よりも優れた状態にすることができます。したがって、ゴールデン ルール #4 (don't push your luck) の精神に則り、失敗した場合、他の多くの人々も同じように文句を言う理由があるという立場に身を置くことです。
timing に関するこの議論からのもう 1 つの洞察は、使用されている FPGA に関して clockの周波数が高い場合、ダブル metastability guard が良い考えかもしれないということです。これは、上記で提案された追加の timing constraint が使用されていない場合に特に当てはまります。 前述のように、 metastability は pathの slackを消費します。 clock period が小さくなる (周波数が高くなる) と、多くの場合 slackが少なくなり、 metastabilityの余分な時間が少なくなります。
最後に、 timingに関するこの問題をほとんどすべての人が無視しているのに、問題について誰も文句を言わないのはなぜかを考えてみましょう。考えられる説明をいくつか挙げますが、これらは単なる推測にすぎません。
したがって、最初の説明は、ツールが metastability guard を FPGAの logic fabric と他の flip-flopの物理的に非常に近くに配置する可能性が高いということです。したがって、これら 2 つの flip-flops (たとえば、 @bar_metaguard から @bar) の間の propagation delay は、その FPGA に関して非常に短いです。ただし、上記で説明したように、明示的な timing constraintsがないと、このタイトな配置は保証されません。
FPGAのベンダーによって提供される公式の FIFOs の内部では、この種の flip-flops のペアが同じ sliceでよく見られます。とにかく、公式の FIFOs は、この問題を解決してくれると信頼できます。
もう 1 つのことは、 FPGAs がより高速になり、 clock の周波数がより高くなるにつれて、 flip-flops も metastability からより速く抜け出すことが判明したことです。したがって、 metastability と propagation delayから回復するのにかかる時間は、 clockの clock period よりも大幅に短いままです。
したがって、ほとんどの人が metastability guard を追加するだけで、もう心配する必要がないことは驚くことではありません。ただし、 constraintの追加を怠る言い訳にはなりません。
clocksの周波数の制限
clock domainの clocks の周波数については、これまであまり語っていません。たとえば、送信元の clock domain (@clk1) の clock が送信先の clock (@clk2) よりも高速な場合はどうなりますか?
clocks間で同期が必要ないため、ソースの周波数自体が高いか低いかは関係ありません。ただし、送信元の信号 (@foo) の変化が速すぎると、送信先の flip-flop がこの変化をサンプリングする機会を得る前に、前後に変化する可能性があります。したがって、宛先ですべてのトランジションを表示する必要がある場合は、ソースの clock period を宛先の clockよりも少し長くする (つまり、周波数を低くする) 必要があります。
後どのくらい?それほどではありません。または、正確な答えを主張する場合: それは主に目的地の timing requirements または flip-flop に依存します。簡単な計算は次のとおりです (本当に興味がない限り、これをスキップしてください)。
この flip-flopの input が、その flip-flopの clock edgeの直前に tsu だけ変化した場合、適切にサンプリングされる寸前なので、次の clock cycleでサンプリングされる必要があります。そうでない場合、この変化が見逃されている可能性があります。次の clock cycle でこの変化を確実にサンプリングするには、 input signal が次の clock edgeの後の thold まで安定していなければなりません。したがって、ソースの clock period は、宛先の clock period よりも tsu + thold + 2tj長くなければなりません。 tj は、 clock period (jitter) の不確実性です。 jitter は 2 回カウントされ、1 回はソースの clock 、2 回目は destinationの clockです。
したがって、 tsu + thold + 2tj は、ソースの clockに対して「少し長い」 clock period を意味するものです。
metastability guardsについてツールに伝える
一部の FPGA ツールのドキュメントでは、 metastability guardsとして使用される attribute を flip-flops に追加することを推奨しています。これにより、ツールがこれらの flip-flopsを操作できなくなります。また、ツールが次の flip-flopと同じ slice に metastability guard を配置することを奨励するため、 routing は可能な限り短くなります。
たとえば、 Vivado には ASYNC_REGという名前の attribute があります。前と同様に、すべての metastability guard registers に *_metaguard サフィックスがある場合、 XDC ファイルの次の行は、必要に応じて attribute を設定します。
set_property ASYNC_REG true [get_cells -hier -filter {name=~*_metaguard*}]
この attribute を Verilog コード内に設定することもできます。
ただし、ツールは通常 metastability guards をとにかく正しく処理するため、この attribute が違いを生む可能性はほとんどありません。
これで、このシリーズの 2 ページ目は終了です。次のページでは、 clock domains間でデータを渡すためのテクニックを示します。