このページは、 Multi-Gigabit Transceiver (MGT) を紹介する一連のページの 4 番目です。前のページでは、 MGT と、それと一緒に使用されるいくつかの protocols 、およびいくつかのエンコード方法について説明しました。
序章
このシリーズの最初のページですでに述べたように、 MGT は SERDESの洗練されたバージョンにすぎません。洗練されたバージョンに仕上げた理由の 1 つは、 MGT 内に特定の protocolsの実装に役立ついくつかの構成要素があることです。このページでは、これらの構成要素のいくつかの背景にある原理について説明します。
MGT でこれらのユニットを含む部分は、通常、 PCS (Physical Coding Sublayer)と呼ばれます。この名前は誤解を招くもので、 PCS 内の logic の一部は、エンコードにもデコードにも何の関係もありません。
これは典型的な MGTのブロック図であり、 PCSが全体的なコンテキストの中でどのような位置を占めているかを示しています。
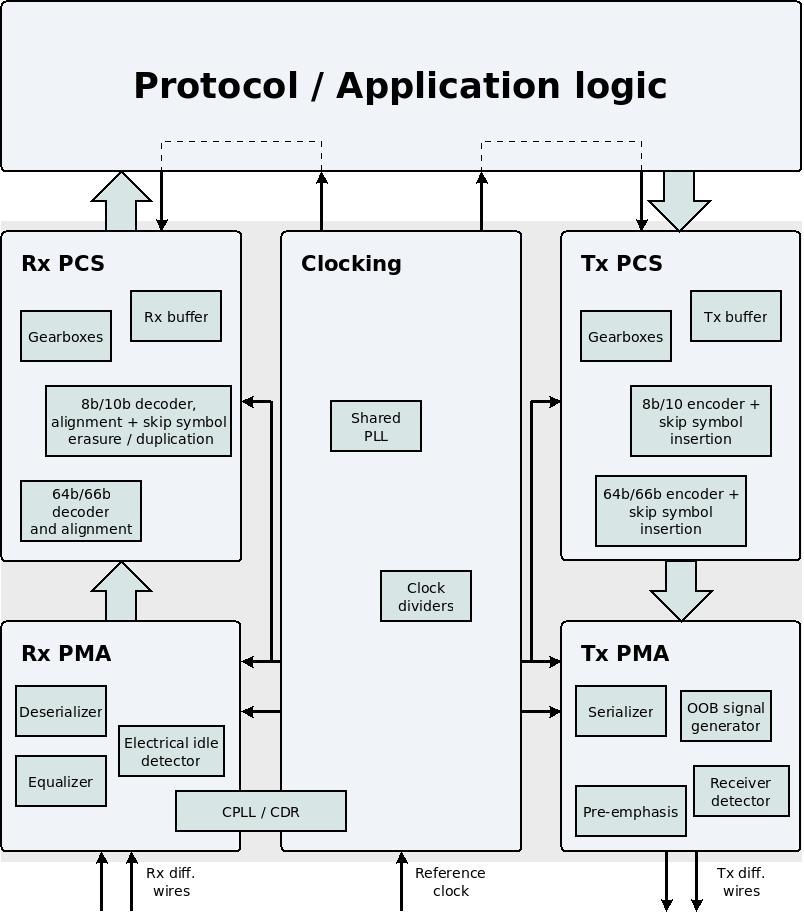
PCS は、 PMA と user application logicの間のすべてで構成されます。 MGT のデータ送信に使用される部分については、 Tx PMA と Tx PCS という表現を使用します。同様に、 Rx PMA と Rx PCS は、データ受信に使用される部分の表現です。
Tx PCS は input ports から始まり、 application logic はデータを MGTに渡して送信します。 Tx PCS は、物理ワイヤ経由で送信する準備が整った bits で構成されるパラレル ワードが存在するときにその役割を終了します。このパラレル ワードは、シリアル化と電気信号への変換を目的として Tx PMA 部分に渡されます。
同様に、 Rx PCS は、 Rx PMA が受信してデシリアル化したデータのパラレル ワードで始まり、 MGT がデータを application logicに渡す output ports で終了します。
PCS はパラレルワードのみを操作する logic で構成されているため、 PCSの機能はすべて logic fabricに実装できることは明らかです。しかしながら、この logic は、多くの構成要素が hard IPsに実装されているのと同じ理由で、 MGT 内に実装されています。一部の protocols は PCSのエンコード機能を活用しています。その他の protocols (例: xillyp2p )は、独自のデータストリーム処理方法を採用しているため、この設計例に示すように、 MGT の使用ははるかにシンプルになっています。
MGT はそれぞれ内部構造が異なるため、 MGTの PCS 内部の詳細なデータ フローを、すべての MGTsを網羅する方法で説明することは不可能です。したがって、以下の説明は、 PCSの機能ブロックが達成しようとしていることに焦点を当てています。 PCS とその構成要素の詳細な説明は、 MGTのドキュメントでのみ見つけることができます。以下の説明により、このドキュメントの読みやすさが向上するはずです。
エンコードとデコード
前のページではいくつかのエンコード方法が紹介されました。 8b/10b、 64b/66b、 64b/67b、 128b/130b 、 128b/132b。
8b/10b の実装は、 PCS内のすべての FPGA MGTsの一部です。実装には、8 ビット ワードを 10 ビット ワードにエンコードおよびデコードする機能 (およびその逆) のほか、前のページで説明したその他の機能が含まれます。 K-symbolsは、 comma symbol (K28.5) に応答して同期とアライメントを行い、 skip symbols (K28.0) にも応答します。
その他のエンコード方式については、 MGT ごとに異なるエンコード セットが実装されています。 MGTs では、エンコードのどの機能が実装されているかによっても異なります。 MGTの PCS では、必要な gearboxのみが実装されている場合もあれば、自動同期のメカニズムも組み込まれている場合もあります。標準的な機能セットはありません。
Gearboxes
PCS 全体および application logicとのインターフェイスでは、物理チャネル上のデータ ストリームはパラレル ワードで表されます。このパラレル ワードの幅は、データが PCS内のさまざまな処理ステップを通過するときに変化することがあります。たとえば、データが 8b/10b エンコーダーを通過すると、ワード幅は 8 ビットから 10 ビットに変わります。
ただし、 MGT との間でアプリケーション データを送受信するためのインターフェイスは、常に 8 の倍数の幅を持つ input ports と output ports で構成されます。通常、この幅は 16、 32、 40、 64、 80、 128 、または 160 bitsのいずれかです。
しかし、たとえば 64b/66b エンコーディングを使用するとどうなるでしょうか。このエンコーディングでは、物理チャネル上のデータ ストリームは、それぞれ 66 bits の長さのセグメントで構成されます。このデータが 64 bits 幅の並列ワードで提供される場合、各セグメントの先頭は、このワード内の毎回異なる位置に表示されます。 application logicとのインターフェイスで許可されている幅の中で、この問題を回避できるものはありません。
これが gearbox の目的です。 input port に到着したデータを異なる幅の並列ワードに再編成する logic module です。
たとえば、 MGTを利用して 64b/66b でエンコードされたデータを送信したいとします。エンコーダーは application logicに実装されています。エンコーダーの output は 66 bits 幅ですが、 MGTの input は 64 または 80 bits 幅 (または、関連性の低い他の選択肢) のいずれかになります。これを解決するには、既存の並列ワード (66 bits 幅) を MGT が受け入れ可能なワード (64 bits 幅) に再編成する gearbox を実装する必要があります。これは避けた方がよい状況です。
このため、 MGTs の PCS 部分には 1 つまたは複数の gearboxes が含まれていることがよくあります。特に、 MGT に 64b/66b エンコーダー (または 128b/130bなどの類似のエンコーダー) が含まれている場合、 MGT内に適切な gearbox もあります。このようにして、 MGT はエンコードされたデータの送信に必要なすべてのタスクを処理します。 まず、データは MGTのエンコーダーでエンコードされ、次に gearbox はパラレル ワードの幅を変更して、このワードを Tx PMA 部分に渡して送信できるようにします。データの受信にも同様のソリューションが使用されます。
gearbox の両側のワードが異なるため、 gearbox に入る bits の数は、そこから出る bits の数とは異なります。 inputの並列ワードの方が広い場合、これを補正するために、 gearbox は時々ワードの受信を拒否する必要があります。同様に、 outputの並列ワードの方が広い場合、 gearbox の output portに有効なものが常に存在するとは限りません。したがって、 gearbox が 1 つの clockのみで動作する場合、両側の bits の量の差を補正するフロー制御信号も必要です。 Xilinx / AMDの用語では、これは synchronous gearboxと呼ばれます。
あるいは、 gearbox は 2 つの clocksに依存することができます。これらの clocks のうちの frequencies は、 gearboxの両側のワード幅の比率を補正するように選択されます。この方法の利点は、データ フローが gearboxのどちらの側でも停止されないことです。ただし、この種の gearbox には 2 つの clocks が必要で、2 つの clock domainsで動作します。このソリューションは asynchronous gearboxと呼ばれます。
Tx buffer (Tx FIFO)
Tx buffer (多くの場合、 Tx FIFOと呼ばれます) は、 Tx PCS内の小さな FIFO です。この FIFOの深さは通常 16 または 32 のデータ要素で、通常の動作状態では通常半分が満たされています。この FIFO の必要性はやや複雑で、以下で説明します。ただし、この説明では、 MGTを構成するときに通常関連する唯一の質問には答えられません。 Tx buffer を有効にするかどうか?
答えは、ほとんどの場合、 Tx buffer を有効にする必要があるということです。 Tx buffer の使用を避ける唯一の理由は、その遅延が問題を引き起こす場合です。 Tx buffer を使用すると、パラレル ワードが MGT に渡されてから、このワードが物理層で送信されるまでの遅延が不明になります。ほとんどのアプリケーションでは、これは 0.1μs程度かそれ以下の不確実性を意味するため、 protocol はこの遅延には無関係です。
この FIFO がなぜ必要なのかについては、次のように説明します。
Tx PCS内には少なくとも 2 つの clock domains があります。 最初の clock は、 application logicとのインターフェイスに使用されます。2 番目の clock ( XCLKと呼ばれることもあります) は、 Tx PCS がパラレル ワードを Tx PMAに渡すときに使用されます。
MGT 内の clocking については、別のページで別途説明します。 今のところは、なぜ 2 つの別個の clocksが存在する必要があるのかを理解するだけで十分です。 これを説明するには、 MGT を通常の SERDESと比較します。
たとえば、通常の output pinを利用して 1000 Mbits/s の速度でデータを送信したいとします。現在、ほとんどの FPGAs には、この目的のために各 output pin に SERDES が接続されています。この例では、 application logic が SERDES に 8 bits 幅の並列ワードを供給すると仮定します。したがって、この並列ワードの clock は 125 MHzです。
したがって、 SERDES には 2 つの clocksが供給されます。 1 つの 125 MHz clock、および 500 MHzの frequency を持つ 2 番目の clock 。 SERDES は clock edges と 500 MHz clockの両方を使用するため、データは必要な速度 1000 MHzで送信されます。
SERDES が受信する 2 つの clocks は、整列している必要があります。たとえば、 500 MHz clock の rising edge は、 125 MHz clockの rising edge と同時に発生する必要があります。これは、 SERDESが適切に動作するために必要です。この整列は、1 つの PLL を使用して両方の clocksを作成し、同じ propagation delayを持つ clock buffers を使用することで実現されます。これは、 clocks が整列していることを保証するための通常の方法です。 関連する clocksについての説明を参照してください。
しかし、 5000 bits/sを送信したい場合はどうでしょうか。これは通常の output pinには大きすぎるため、 MGT が必要です。 MGT 内にも SERDES があります。この SERDES に該当するパラレル ワードの幅が 32 bitsであると仮定します。したがって、このワードに関連付けられている clock の frequency は 156.25 MHzです。また、 application logic とのインターフェイスが、同じく 32 bits 幅のパラレル ワードで構成されていると仮定します。したがって、このインターフェイスの clock frequency も 156.25 MHz です。しかし、これは同じ clock signalでしょうか。
パラレル ワードを送信するには、 MGTの SERDES を 2500 MHz clock に接続する必要があります (新しい bit は両方の clock edgesで送信されます)。この frequency は、 FPGAの汎用 PLLsには高すぎます。また、この clockに FPGAの clock buffers または他の routing resources を使用することもできません。したがって、 SERDES に必要な 2 つの整列した clocks を生成するために、 MGT には独自の PLLs と wires が必要です。これについての詳細は、 MGTの clockingに関するページを参照してください。
これで、 Tx PCS内に少なくとも 2 つの clock domains が存在する理由が理解できました。この例では、 Tx PCS は Tx PMA に 32 bits 幅の並列ワードを供給します。このワードの clock は 156.25 MHzです。この clock は、 2500 MHz clockとのアラインメントを確保するために、 MGTの PLL によって作成されます。 application logic と MGT 間のインターフェイスはまったく同じ clock frequencyに基づいていますが、 application logic は、これにもかかわらず同じ clock signal を使用できません。 application logicの clock は、logic fabricの clock buffer を通過する必要があります。そうすることで、この clock は skewなしですべての logic elements に到達します。この clock bufferの遅延により、 application logicの clock は 2500 MHz clockと自然に揃いません。
clock domain crossing の場合、最も簡単な方法は、 FIFO を使用することです (このトピックについて説明しているページに記載されているとおり)。 Tx buffer は、この FIFOです。
Tx bufferをバイパスするオプションを提供するMGTでは、 Tx PCS内の clocks 間で必要なアライメントを確実に行うための他の方法も提供されています。ただし、これらの方法は複雑で、エラーが発生しやすくなります。
Rx buffer (Rx FIFO)
Rx buffer ( Rx FIFOと呼ばれることが多い) は、 Rx PCSの中に入っている小さな FIFO です。原理的には、この buffer は Tx bufferと同じなので、上記の Tx buffer に関する説明はすべて Rx buffer にも当てはまります。特に、この buffer を有効にするかどうかの答えは同じです。 Rx buffer は、それによって引き起こされる遅延が許容できない場合を除き、ほとんどのアプリケーションで有効にする必要があります。
ただし、 Rx buffer には追加の目的があります。 これにより、 Rx PCS は、 frequenciesとは若干異なる 2 つの clocks と連携できるようになります。次に、この違いが発生する理由について説明します。
まず、この説明はデータ ストリームを受信する MGT の部分に焦点を当てていることを思い出してください。ただし、このデータ ストリームは別の MGTによって生成され、別の reference clock に依存しています (ほとんどのシナリオでは)。データ ストリームを受信する MGT は、送信側が使用する clock にアクセスできないことがよくあります。代わりに、受信側はデータ ストリームのみに基づいてこの clock のレプリカを作成します (これをCDR, Clock Data Recoveryと呼びます)。
その結果、 Rx PMA は、送信機のデータ レートに適応する clock と連動します。この clock の frequency は、定義された許容範囲内で不確実です。 protocol は常に、 frequency が指定された数値からどれだけ逸脱できるかを定義しますが、常に一定レベルの不確実性が存在します。
したがって、 Rx PMA から Rx PCS にパラレル ワードを渡すためのインターフェイスは、送信機に適応する clock に依存します。 Rx PCS は、外部の clockと同期している必要があります。
しかし、なぜこれが Tx PCSと異なるのでしょうか? Tx buffer についての説明で、 Tx PCSの一部に two clock domains があることを思い出してください。これら 2 つの clocks は同じ clock signalではありませんが、同じ reference clockに基づいているため、 frequencyはまったく同じです。
同様に、 Rx PCSの一部には 2 つの clock domains があります。 clocks の 1 つには不明な frequencyがあります。もう 1 つの clockはどうでしょうか。答えは、 application logicの要件によって異なります。 ほとんどのシナリオでは、 MGT は双方向 protocolを実装するために使用されます。この protocol では、受信したデータに応答してデータを送信します。したがって、すべての application logic が 1 つの clockと同期していると便利です。より具体的には、最も一般的なソリューションは、すべての application logic が送信に使用される clock と同期することです。つまり、 Rx PCS と application logic 間のインターフェイスは、 Tx PCSの場合と同じ clock と同期します。
このアプローチを採用すると、 Rx PCS 内の 2 つの clocks は同じ frequencyを持ちません。その結果、 Rx PCS は Rx PMA からデータを受信しますが、その速度は application logicにデータを渡す速度とは異なります。 Rx buffer は、この差を一時的に吸収することができます。 application logic が遅い速度でデータを取得する場合、 Rx buffer は余剰分を蓄積します。 application logic が速い速度でデータを取得する場合、 Rx buffer は徐々に空になります。
もちろん、これは非常に一時的な解決策です。 Rx buffer は、その容量の半分程度に充填レベルを維持する何らかの措置を講じない限り、遅かれ早かれオーバーフローするか空になります。この目的のためにはさまざまなメカニズムがあります。たとえば、前のページで説明したように、 8b/10b エンコーディングを使用する場合、 clock frequencies間の差異を補正するために skip symbols を挿入できます。 skip symbols を利用するメカニズムは、 Rx PCS内に実装されています。 Rx buffer が半分以上いっぱいの場合、 Rx PCS は skip symbols を Rx bufferに書き込まないため、充填レベルが低下します。一方、 Rx buffer が半分未満の場合、 Rx PCS は Rx buffer から skip symbols を繰り返し読み取ります。その結果、この buffer が空にならないのと同時に、新しいデータが buffer に充填されます。したがって、 Rx bufferの充填レベルが増加します。
Rx buffer は、充填レベルの差を一時的に吸収するこの機能があるため、 elastic bufferと呼ばれることがよくあります。この機能は必ずしも必要ではないことに注意することが重要です。 application logic が、 Rx PMAの clockと同じ frequency を持つ clock を介して Rx PCS とインターフェースする場合、 Rx buffer は原則として Tx bufferと同じように動作します。このアプローチを採用する場合、必要に応じて application logic が clock domain crossingの実装を担当します。このアプローチでは、必要に応じて Rx buffer を無効にすることもできます(特に遅延を回避するため)。Xillyp2pは、 Rx PMAの clockでデータを受信しますが、 clockingを簡素化するために Rx buffer を使用できる application logic の例です。
pseudo-random sequencesに関連する機能
pseudo-random bit sequence (PRBS) は、ランダムのように見える bits のシーケンスですが、実際にはランダムではありません。 PRBS は周期的に繰り返されます。非常に長い周期 (数百万 bits) の PRBS を生成するのは簡単なので、 PRBS の統計的特性は、 bitsの完全にランダムなシーケンスの統計的特性に似ています。
PRBS を生成する最も一般的な方法は、 Linear-Feedback Shift Register (LFSR) を利用することです。この logic はいくつかの flip-flops と XOR gatesで構成されているため、 LFSR を実装するのに多くのリソースは必要ありません。よく使用される LFSR の例は、 LFSRsに関連する数学的なトピックについて説明している別のページにあります。
MGT の PCS 部分には、通常、 PRBSに関連する機能がいくつかあります。特に、 MGT には scramblerの実装がある場合があります。 Rx PCSに scrambler の同期が実装されると、作業が大幅に削減されます。
PRBS のもう 1 つの非常に一般的な用途は、物理チャネルのエラーをテストすることです。これは、受信機が LFSRの助けを借りて bits の正しいシーケンスを簡単に生成できるため、便利な方法です。物理チャネルのエラーは、ローカルで生成された bit sequence を到着したデータ ストリームと比較することによって検出されます。このメカニズムを logic fabricに実装するのは難しくありませんが、一部の MGTs にはこの機能が組み込まれています。
残念ながら、 PRBSを用いたエラーテスト中は、物理チャネルをデータ送信に使用できません。そのため、実際に使用されているチャネルの品質を監視することはできません。一部の protocols にはエラー報告機構が搭載されていますが、通常は送信データが中断された場合にのみエラーが報告されます。唯一の例外はxillyp2pで、リンクがアイドル状態のときに発生したエラーも報告します。
これで、 MGTsに関するこのシリーズの 4 ページ目は終了です。次のページでは、 PMA と、難しい物理チャネルを補正する機能、および eye scanningを実行する機能について説明します。